 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyp detection in colonoscopy images using YOLOv11
Jan 15, 2025



Colorectal cancer (CRC) is one of the most commonly diagnosed cancers all over the world. It starts as a polyp in the inner lining of the colon. To prevent CRC, early polyp detection is required. Colonosopy is used for the inspection of the colon. Generally, the images taken by the camera placed at the tip of the endoscope are analyzed by the experts manually. Various traditional machine learning models have been used with the rise of machine learning. Recently, deep learning models have shown more effectiveness in polyp detection due to their superiority in generalizing and learning small features. These deep learning models for object detection can be segregated into two different types: single-stage and two-stage. Generally, two stage models have higher accuracy than single stage ones but the single stage models have low inference time. Hence, single stage models are easy to use for quick object detection. YOLO is one of the singlestage models used successfully for polyp detection. It has drawn the attention of researchers because of its lower inference time. The researchers have used Different versions of YOLO so far, and with each newer version, the accuracy of the model is increasing. This paper aims to see the effectiveness of the recently released YOLOv11 to detect polyp. We analyzed the performance for all five models of YOLOv11 (YOLO11n, YOLO11s, YOLO11m, YOLO11l, YOLO11x) with Kvasir dataset for the training and testing. Two different versions of the dataset were used. The first consisted of the original dataset, and the other was created using augmentation techniques. The performance of all the models with these two versions of the dataset have been analysed.
Inverse kinematics learning of a continuum manipulator using limited real time data
Mar 27, 2024Data driven control of a continuum manipulator requires a lot of data for training but generating sufficient amount of real time data is not cost efficient. Random actuation of the manipulator can also be unsafe sometimes. Meta learning has been used successfully to adapt to a new environment. Hence, this paper tries to solve the above mentioned problem using meta learning. We consider two cases for that. First, this paper proposes a method to use simulation data for training the model using MAML(Model-Agnostic Meta-Learning). Then, it adapts to the real world using gradient steps. Secondly,if the simulation model is not available or difficult to formulate, then we propose a CGAN(Conditional Generative adversial network)-MAML based method for it. The model is trained using a small amount of real time data and augmented data for different loading conditions. Then, adaptation is done in the real environment. It has been found out from the experiments that the relative positioning error for both the cases are below 3%. The proposed models are experimentally verified on a real continuum manipulator.
Hybrid CNN Bi-LSTM neural network for Hyperspectral image classification
Feb 15, 2024



Hyper spectral images have drawn the attention of the researchers for its complexity to classify. It has nonlinear relation between the materials and the spectral information provided by the HSI image. Deep learning methods have shown superiority in learning this nonlinearity in comparison to traditional machine learning methods. Use of 3-D CNN along with 2-D CNN have shown great success for learning spatial and spectral features. However, it uses comparatively large number of parameters. Moreover, it is not effective to learn inter layer information. Hence, this paper proposes a neural network combining 3-D CNN, 2-D CNN and Bi-LSTM. The performance of this model has been tested on Indian Pines(IP) University of Pavia(PU) and Salinas Scene(SA) data sets. The results are compared with the state of-the-art deep learning-based models. This model performed better in all three datasets. It could achieve 99.83, 99.98 and 100 percent accuracy using only 30 percent trainable parameters of the state-of-art model in IP, PU and SA datasets respectively.
Guidance system for Visually Impaired Persons using Deep Learning and Optical flow
Oct 22, 2023
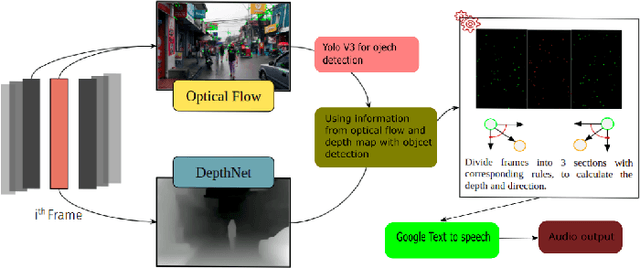

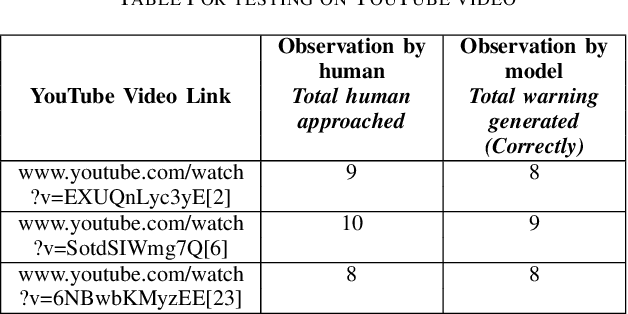
Visually impaired persons find it difficult to know about their surroundings while walking on a road. Walking sticks used by them can only give them information about the obstacles in the stick's proximity. Moreover, it is mostly effective in static or very slow-paced environments. Hence, this paper introduces a method to guide them in a busy street. To create such a system it is very important to know about the approaching object and its direction of approach. To achieve this objective we created a method in which the image frame received from the video is divided into three parts i.e. center, left, and right to know the direction of approach of the approaching object. Object detection is done using YOLOv3. Lucas Kanade's optical flow estimation method is used for the optical flow estimation and Depth-net is used for depth estimation. Using the depth information, object motion trajectory, and object category information, the model provides necessary information/warning to the person. This model has been tested in the real world to show its effectiveness.