 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifying with Uncertain Data Envelopment Analysis
Sep 02, 2022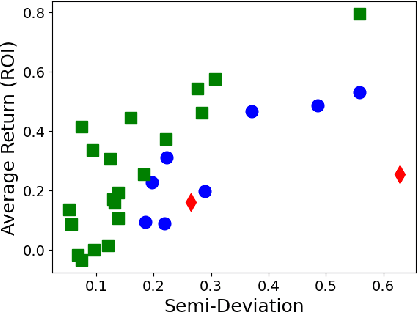
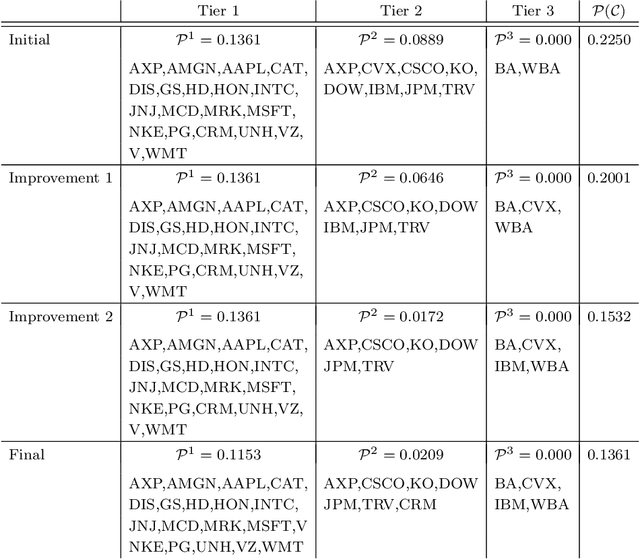
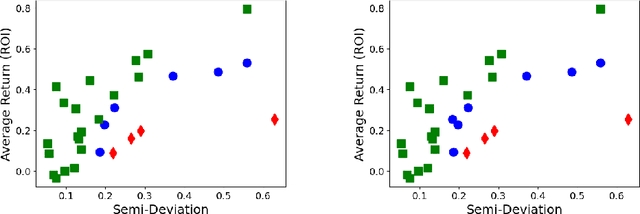
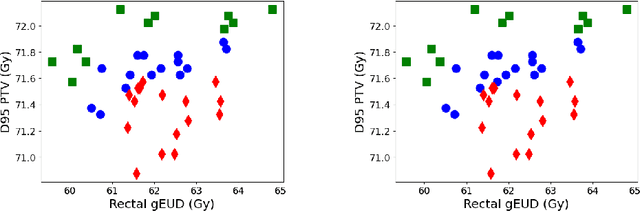
Classifications organize entities into categories that identify similarities within a category and discern dissimilarities among categories, and they powerfully classify information in support of analysis. We propose a new classification scheme premised on the reality of imperfect data. Our computational model uses uncertain data envelopment analysis to define a classification's proximity to equitable efficiency, which is an aggregate measure of intra-similarity within a classification's categories. Our classification process has two overriding computational challenges, those being a loss of convexity and a combinatorially explosive search space. We overcome the first by establishing lower and upper bounds on the proximity value, and then by searching this range with a first-order algorithm. We overcome the second by adapting the p-median problem to initiate our exploration, and by then employing an iterative neighborhood search to finalize a classification. We conclude by classifying the thirty stocks in the Dow Jones Industrial average into performant tiers and by classifying prostate treatments into clinically effectual categories.