 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Feature Encoding for GNNs on Road Networks
Mar 02, 2022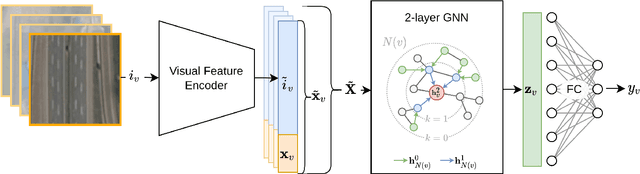
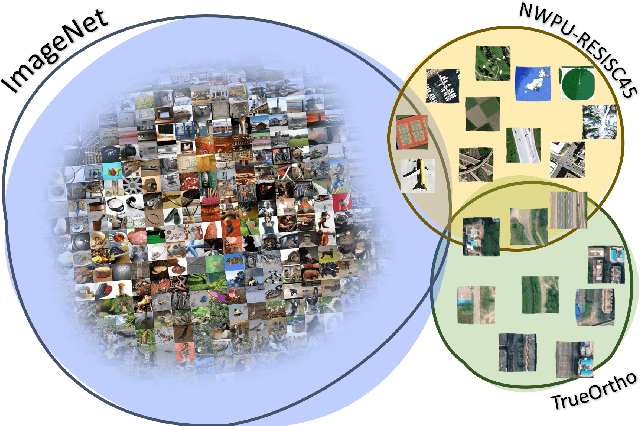


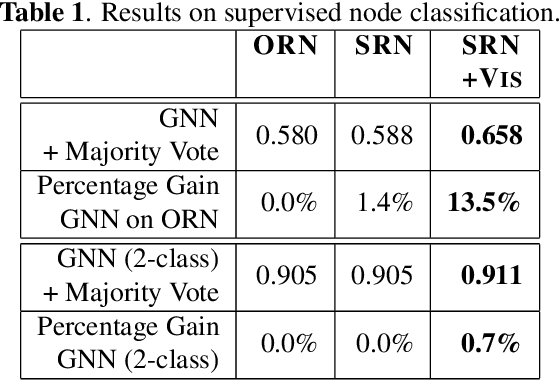
In this work, we present a novel approach to learning an encoding of visual features into graph neural networks with the application on road network data. We propose an architecture that combines state-of-the-art vision backbone networks with graph neural networks. More specifically, we perform a road type classification task on an Open Street Map road network through encoding of satellite imagery using various ResNet architectures. Our architecture further enables fine-tuning and a transfer-learning approach is evaluated by pretraining on the NWPU-RESISC45 image classification dataset for remote sensing and comparing them to purely ImageNet-pretrained ResNet models as visual feature encoders. The results show not only that the visual feature encoders are superior to low-level visual features, but also that the fine-tuning of the visual feature encoder to a general remote sensing dataset such as NWPU-RESISC45 can further improve the performance of a GNN on a machine learning task like road type classification.
Learning to integrate vision data into road network data
Dec 20, 2021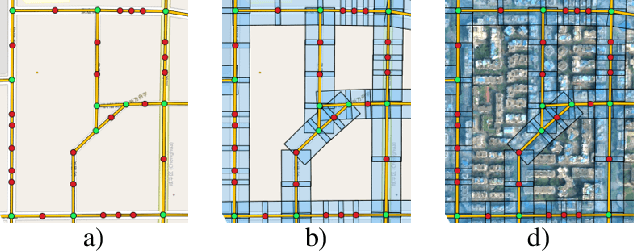
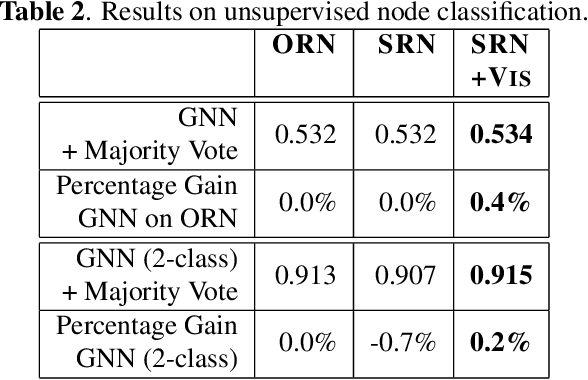
Road networks are the core infrastructure for connected and autonomous vehicles, but creating meaningful representations for machine learning applications is a challenging task. In this work, we propose to integrate remote sensing vision data into road network data for improved embeddings with graph neural networks. We present a segmentation of road edges based on spatio-temporal road and traffic characteristics, which allows to enrich the attribute set of road networks with visual features of satellite imagery and digital surface models. We show that both, the segmentation and the integration of vision data can increase performance on a road type classification task, and we achieve state-of-the-art performance on the OSM+DiDi Chuxing dataset on Chengdu, China.
Landmark2Vec: An Unsupervised Neural Network-Based Landmark Positioning Method
Jan 28, 2020



A Neural Network-based method for unsupervised landmarks map estimation from measurements taken from landmarks is introduced. The measurements needed for training the network are the signals observed/received from landmarks by an agent. The definition of landmarks, agent, and the measurements taken by agent from landmarks is rather broad here: landmarks can be visual objects, e.g., poles along a road, with measurements being the size of landmark in a visual sensor mounted on a vehicle (agent), or they can be radio transmitters, e.g., WiFi access points inside a building, with measurements being the Received Signal Strength (RSS) heard from them by a mobile device carried by a person (agent). The goal of the map estimation is then to find the positions of landmarks up to a scale, rotation, and shift (i.e., the topological map of the landmarks). Assuming that there are $L$ landmarks, the measurements will be $L \times 1$ vectors collected over the area. A shallow network then will be trained to learn the map without any ground truth information.