 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Journalism with AI: A Study of Contextualized Image Captioning for News Articles using LLMs and LMMs
Aug 08, 2024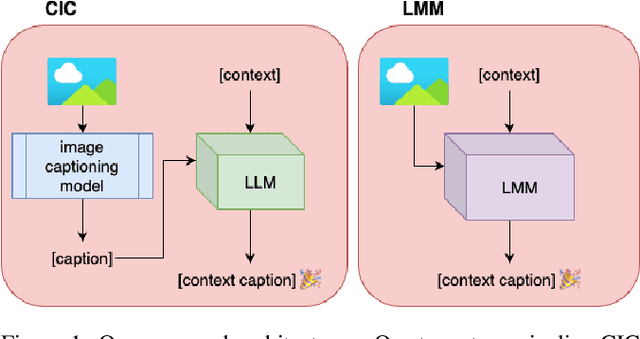


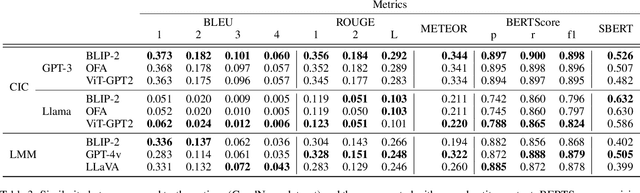
Large language models (LLMs) and large multimodal models (LMMs) have significantly impacted the AI community, industry, and various economic sectors. In journalism, integrating AI poses unique challenges and opportunities, particularly in enhancing the quality and efficiency of news reporting. This study explores how LLMs and LMMs can assist journalistic practice by generating contextualised captions for images accompanying news articles. We conducted experiments using the GoodNews dataset to evaluate the ability of LMMs (BLIP-2, GPT-4v, or LLaVA) to incorporate one of two types of context: entire news articles, or extracted named entities. In addition, we compared their performance to a two-stage pipeline composed of a captioning model (BLIP-2, OFA, or ViT-GPT2) with post-hoc contextualisation with LLMs (GPT-4 or LLaMA). We assess a diversity of models, and we find that while the choice of contextualisation model is a significant factor for the two-stage pipelines, this is not the case in the LMMs, where smaller, open-source models perform well compared to proprietary, GPT-powered ones. Additionally, we found that controlling the amount of provided context enhances performance. These results highlight the limitations of a fully automated approach and underscore the necessity for an interactive, human-in-the-loop strategy.
Putting Humans in the Image Captioning Loop
Jun 06, 2023Image Captioning (IC) models can highly benefit from human feedback in the training process, especially in cases where data is limited. We present work-in-progress on adapting an IC system to integrate human feedback, with the goal to make it easily adaptable to user-specific data. Our approach builds on a base IC model pre-trained on the MS COCO dataset, which generates captions for unseen images. The user will then be able to offer feedback on the image and the generated/predicted caption, which will be augmented to create additional training instances for the adaptation of the model. The additional instances are integrated into the model using step-wise updates, and a sparse memory replay component is used to avoid catastrophic forgetting. We hope that this approach, while leading to improved results, will also result in customizable IC models.
Towards Adaptable and Interactive Image Captioning with Data Augmentation and Episodic Memory
Jun 06, 2023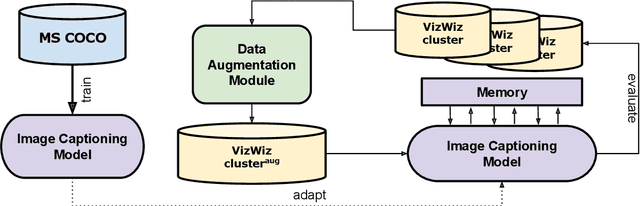


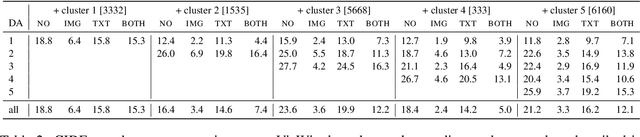
Interactive machine learning (IML) is a beneficial learning paradigm in cases of limited data availability, as human feedback is incrementally integrated into the training process. In this paper, we present an IML pipeline for image captioning which allows us to incrementally adapt a pre-trained image captioning model to a new data distribution based on user input. In order to incorporate user input into the model, we explore the use of a combination of simple data augmentation methods to obtain larger data batches for each newly annotated data instance and implement continual learning methods to prevent catastrophic forgetting from repeated updates. For our experiments, we split a domain-specific image captioning dataset, namely VizWiz, into non-overlapping parts to simulate an incremental input flow for continually adapting the model to new data. We find that, while data augmentation worsens results, even when relatively small amounts of data are available, episodic memory is an effective strategy to retain knowledge from previously seen clusters.
Interactive Machine Learning for Image Captioning
Feb 28, 2022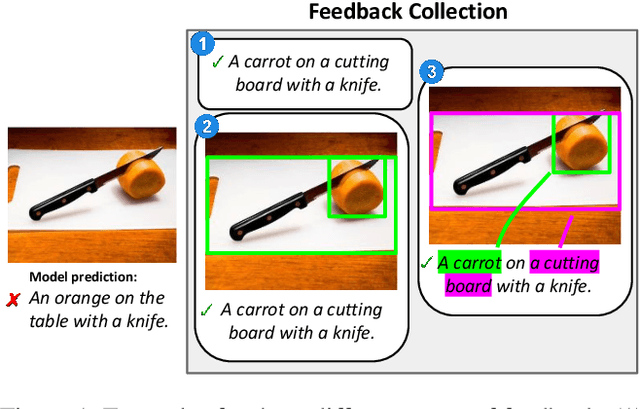
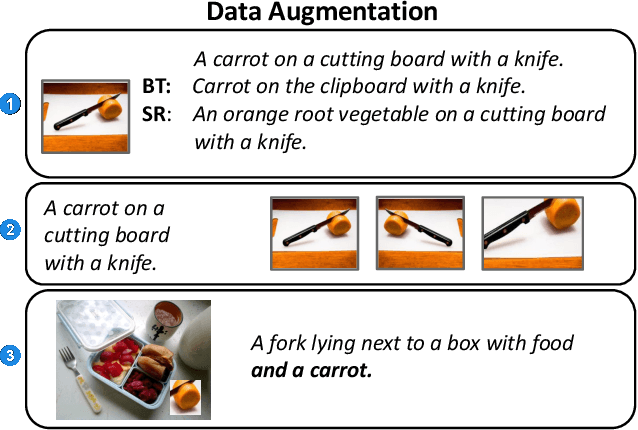
We propose an approach for interactive learning for an image captioning model. As human feedback is expensive and modern neural network based approaches often require large amounts of supervised data to be trained, we envision a system that exploits human feedback as good as possible by multiplying the feedback using data augmentation methods, and integrating the resulting training examples into the model in a smart way. This approach has three key components, for which we need to find suitable practical implementations: feedback collection, data augmentation, and model update. We outline our idea and review different possibilities to address these tasks.