 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for RIS-Assisted FD Systems: Single or Distributed RIS?
Aug 15, 2022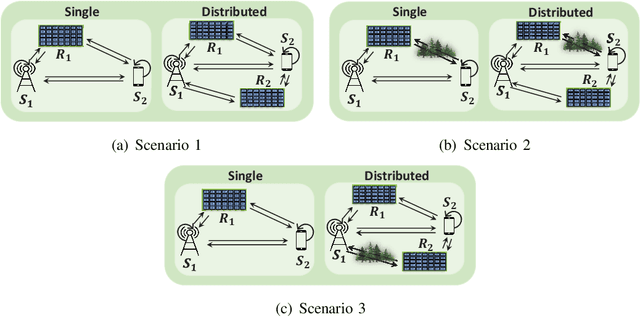
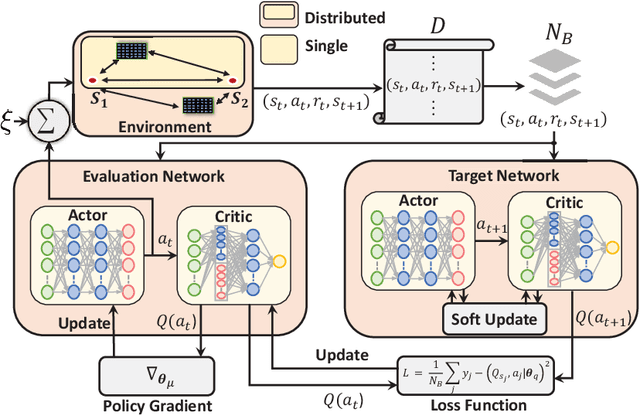
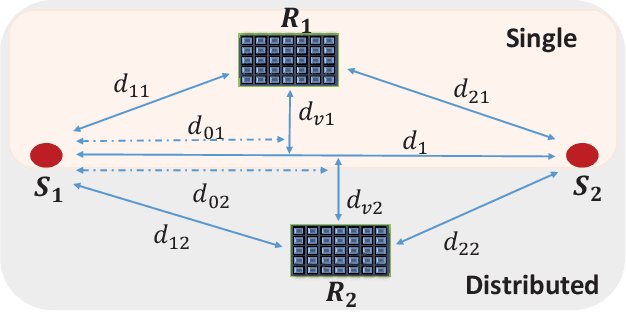
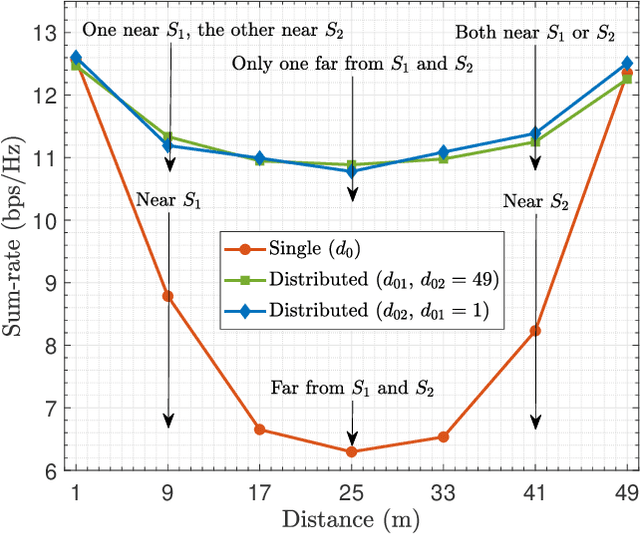
This paper investigates reconfigurable intelligent surface (RIS)-assisted full-duplex multiple-input single-output wireless system, where the beamforming and RIS phase shifts are optimized to maximize the sum-rate for both single and distributed RIS deployment schemes. The preference of using the single or distributed RIS deployment scheme is investigated through three practical scenarios based on the links' quality. The closed-form solution is derived to optimize the beamforming vectors and a novel deep reinforcement learning (DRL) algorithm is proposed to optimize the RIS phase shifts. Simulation results illustrate that the choice of the deployment scheme depends on the scenario and the links' quality. It is further shown that the proposed algorithm significantly improves the sum-rate compared to the non-optimized scenario in both single and distributed RIS deployment schemes. Besides, the proposed beamforming derivation achieves a remarkable improvement compared to the approximated derivation in previous works. Finally, the complexity analysis confirms that the proposed DRL algorithm reduces the computation complexity compared to the DRL algorithm in the literature.
* arXiv admin note: text overlap with arXiv:2110.04859
Deep Reinforcement Learning for Optimizing RIS-Assisted HD-FD Wireless Systems
Oct 10, 2021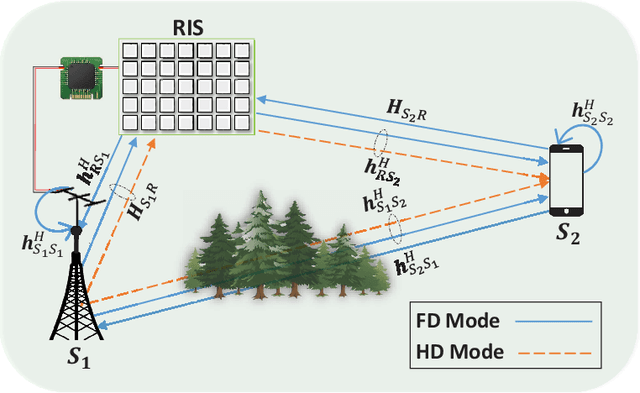
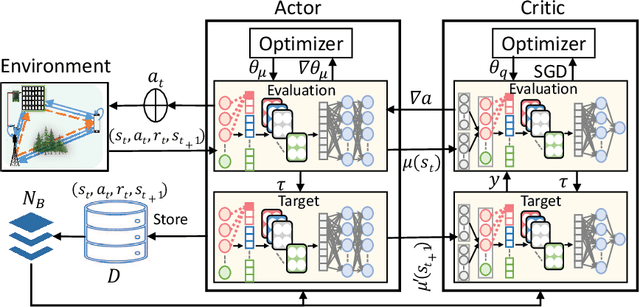
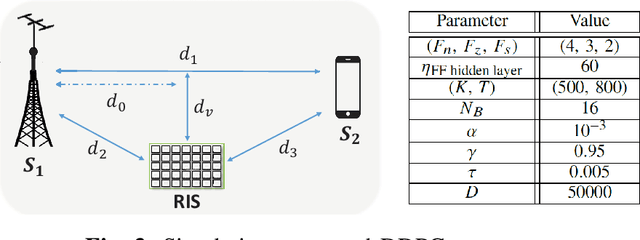

This letter investigates the reconfigurable intelligent surface (RIS)-assisted multiple-input single-output (MISO) wireless system, where both half-duplex (HD) and full-duplex (FD) operating modes are considered together, for the first time in the literature. The goal is to maximize the rate by optimizing the RIS phase shifts. A novel deep reinforcement learning (DRL) algorithm is proposed to solve the formulated non-convex optimization problem. The complexity analysis and Monte Carlo simulations illustrate that the proposed DRL algorithm significantly improves the rate compared to the non-optimized scenario in both HD and FD operating modes using a single parameter setting. Besides, it significantly reduces the computational complexity of the downlink HD MISO system and improves the achievable rate with a reduced number of steps per episode compared to the conventional DRL algorithm.