 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn explainable machine learning-based approach for analyzing customers' online data to identify the importance of product attributes
Feb 03, 2024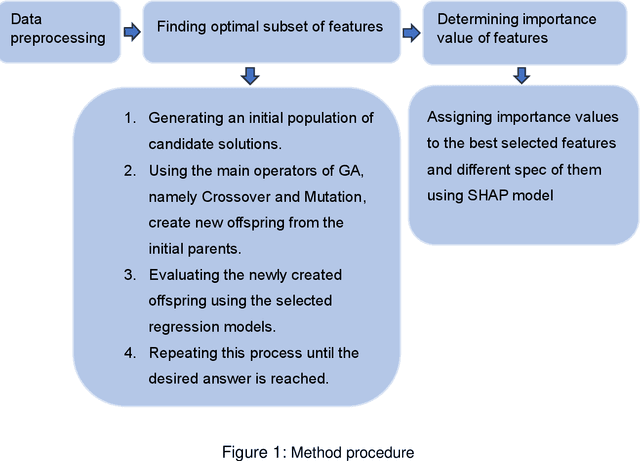



Online customer data provides valuable information for product design and marketing research, as it can reveal the preferences of customers. However, analyzing these data using artificial intelligence (AI) for data-driven design is a challenging task due to potential concealed patterns. Moreover, in these research areas, most studies are only limited to finding customers' needs. In this study, we propose a game theory machine learning (ML) method that extracts comprehensive design implications for product development. The method first uses a genetic algorithm to select, rank, and combine product features that can maximize customer satisfaction based on online ratings. Then, we use SHAP (SHapley Additive exPlanations), a game theory method that assigns a value to each feature based on its contribution to the prediction, to provide a guideline for assessing the importance of each feature for the total satisfaction. We apply our method to a real-world dataset of laptops from Kaggle, and derive design implications based on the results. Our approach tackles a major challenge in the field of multi-criteria decision making and can help product designers and marketers, to understand customer preferences better with less data and effort. The proposed method outperforms benchmark methods in terms of relevant performance metrics.
GWO-FI: A novel machine learning framework by combining Gray Wolf Optimizer and Frequent Itemsets to diagnose and investigate effective factors on In-Hospital Mortality and Length of Stay among Kermanshahian Cardiovascular Disease patients
Dec 26, 2022
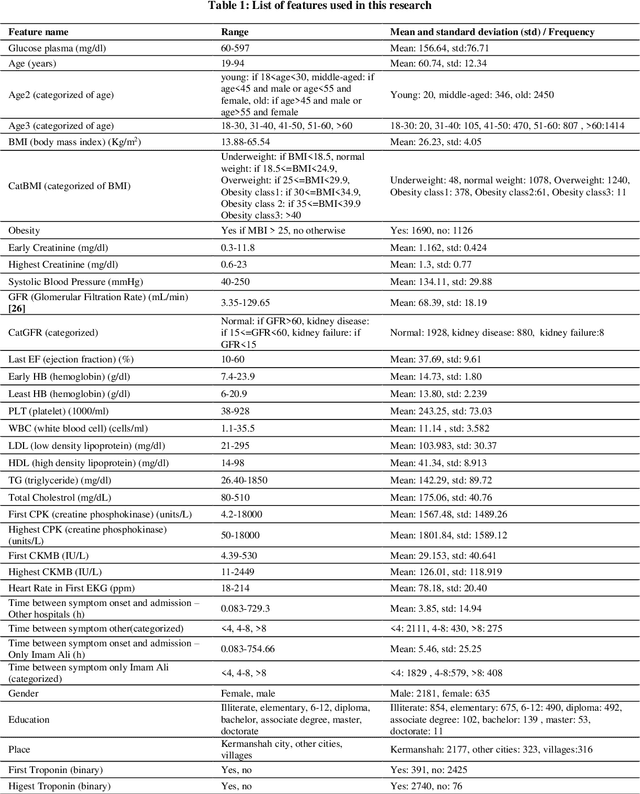

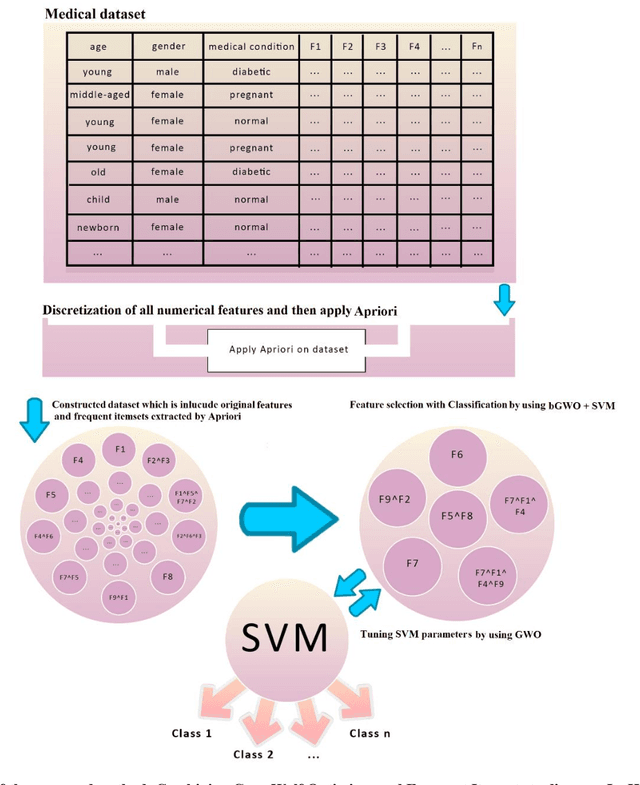
Investigation and analysis of patient outcomes, including in-hospital mortality and length of stay, are crucial for assisting clinicians in determining a patient's result at the outset of their hospitalization and for assisting hospitals in allocating their resources. This paper proposes an approach based on combining the well-known gray wolf algorithm with frequent items extracted by association rule mining algorithms. First, original features are combined with the discriminative extracted frequent items. The best subset of these features is then chosen, and the parameters of the used classification algorithms are also adjusted, using the gray wolf algorithm. This framework was evaluated using a real dataset made up of 2816 patients from the Imam Ali Kermanshah Hospital in Iran. The study's findings indicate that low Ejection Fraction, old age, high CPK values, and high Creatinine levels are the main contributors to patients' mortality. Several significant and interesting rules related to mortality in hospitals and length of stay have also been extracted and presented. Additionally, the accuracy, sensitivity, specificity, and auroc of the proposed framework for the diagnosis of mortality in the hospital using the SVM classifier were 0.9961, 0.9477, 0.9992, and 0.9734, respectively. According to the framework's findings, adding frequent items as features considerably improves classification accuracy.
A Profile-Based Binary Feature Extraction Method Using Frequent Itemsets for Improving Coronary Artery Disease Diagnosis
Sep 22, 2021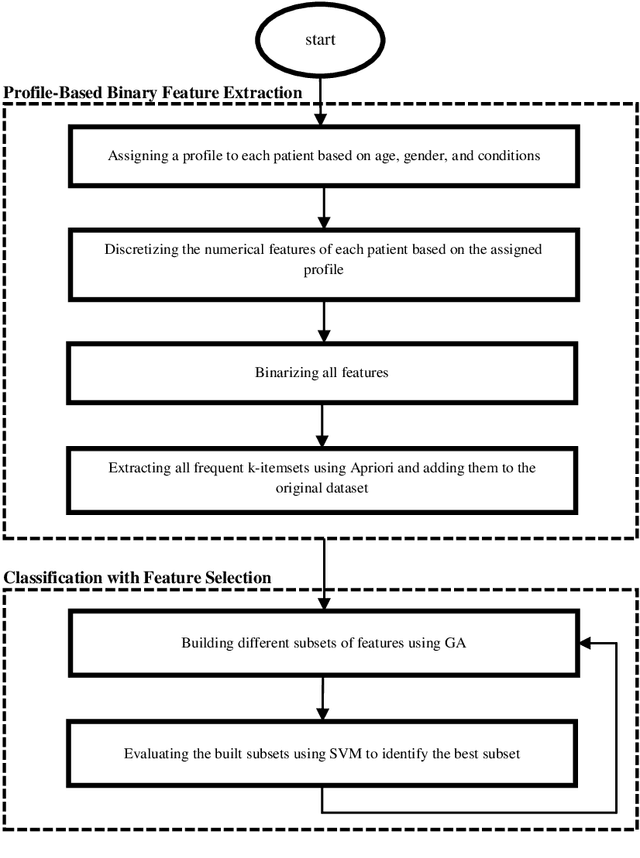
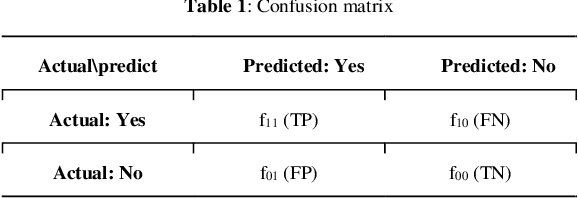
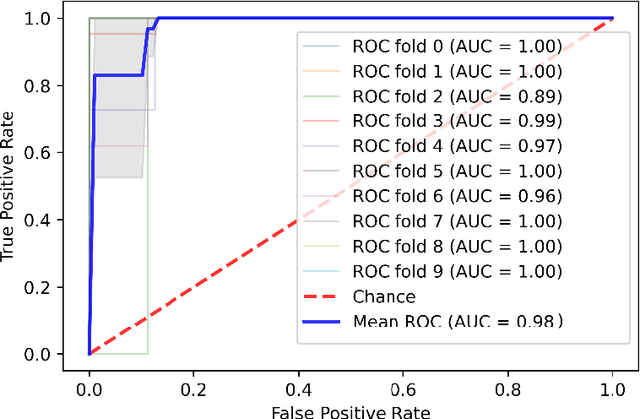
Recent years have seen growing interest in the diagnosis of Coronary Artery Disease (CAD) with machine learning methods to reduce the cost and health implications of conventional diagnosis. This paper introduces a CAD diagnosis method with a novel feature extraction technique called the Profile-Based Binary Feature Extraction (PBBFE). In this method, after partitioning numerical features, frequent itemsets are extracted by the Apriori algorithm and then used as features to increase the CAD diagnosis accuracy. The proposed method consists of two main phases. In the first phase, each patient is assigned a profile based on age, gender, and medical condition, and then all numerical features are discretized based on assigned profiles. All features then undergo a binarization process to become ready for feature extraction by Apriori. In the last step of this phase, frequent itemsets are extracted from the dataset by Apriori and used to build a new dataset. In the second phase, the Genetic Algorithm and the Support Vector Machine are used to identify the best subset of extracted features for classification. The proposed method was tested on the Z-Alizadeh Sani dataset, which is one the richest databases in the field of CAD. Performance comparisons conducted on this dataset showed that the proposed method outperforms all major alternative methods with 98.35% accuracy, 100% sensitivity, and 94.25% specificity. The proposed method also achieved the highest accuracy on several other datasets.