 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGNSS/GPS Spoofing and Jamming Identification Using Machine Learning and Deep Learning
Jan 04, 2025



The increasing reliance on Global Navigation Satellite Systems (GNSS), particularly the Global Positioning System (GPS), underscores the urgent need to safeguard these technologies against malicious threats such as spoofing and jamming. As the backbone for positioning, navigation, and timing (PNT) across various applications including transportation, telecommunications, and emergency services GNSS is vulnerable to deliberate interference that poses significant risks. Spoofing attacks, which involve transmitting counterfeit GNSS signals to mislead receivers into calculating incorrect positions, can result in serious consequences, from navigational errors in civilian aviation to security breaches in military operations. Furthermore, the lack of inherent security measures within GNSS systems makes them attractive targets for adversaries. While GNSS/GPS jamming and spoofing systems consist of numerous components, the ability to distinguish authentic signals from malicious ones is essential for maintaining system integrity. Recent advancements in machine learning and deep learning provide promising avenues for enhancing detection and mitigation strategies against these threats. This paper addresses both spoofing and jamming by tackling real-world challenges through machine learning, deep learning, and computer vision techniques. Through extensive experiments on two real-world datasets related to spoofing and jamming detection using advanced algorithms, we achieved state of the art results. In the GNSS/GPS jamming detection task, we attained approximately 99% accuracy, improving performance by around 5% compared to previous studies. Additionally, we addressed a challenging tasks related to spoofing detection, yielding results that underscore the potential of machine learning and deep learning in this domain.
Self-Supervised In-Domain Representation Learning for Remote Sensing Image Scene Classification
Feb 03, 2023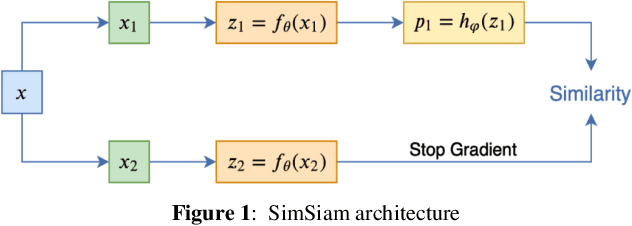



Transferring the ImageNet pre-trained weights to the various remote sensing tasks has produced acceptable results and reduced the need for labeled samples. However, the domain differences between ground imageries and remote sensing images cause the performance of such transfer learning to be limited. Recent research has demonstrated that self-supervised learning methods capture visual features that are more discriminative and transferable than the supervised ImageNet weights. We are motivated by these facts to pre-train the in-domain representations of remote sensing imagery using contrastive self-supervised learning and transfer the learned features to other related remote sensing datasets. Specifically, we used the SimSiam algorithm to pre-train the in-domain knowledge of remote sensing datasets and then transferred the obtained weights to the other scene classification datasets. Thus, we have obtained state-of-the-art results on five land cover classification datasets with varying numbers of classes and spatial resolutions. In addition, By conducting appropriate experiments, including feature pre-training using datasets with different attributes, we have identified the most influential factors that make a dataset a good choice for obtaining in-domain features. We have transferred the features obtained by pre-training SimSiam on remote sensing datasets to various downstream tasks and used them as initial weights for fine-tuning. Moreover, we have linearly evaluated the obtained representations in cases where the number of samples per class is limited. Our experiments have demonstrated that using a higher-resolution dataset during the self-supervised pre-training stage results in learning more discriminative and general representations.
Supervised and Contrastive Self-Supervised In-Domain Representation Learning for Dense Prediction Problems in Remote Sensing
Jan 29, 2023In recent years Convolutional neural networks (CNN) have made significant progress in computer vision. These advancements have been applied to other areas, such as remote sensing and have shown satisfactory results. However, the lack of large labeled datasets and the inherent complexity of remote sensing problems have made it difficult to train deep CNNs for dense prediction problems. To solve this issue, ImageNet pretrained weights have been used as a starting point in various dense predictions tasks. Although this type of transfer learning has led to improvements, the domain difference between natural and remote sensing images has also limited the performance of deep CNNs. On the other hand, self-supervised learning methods for learning visual representations from large unlabeled images have grown substantially over the past two years. Accordingly, in this paper we have explored the effectiveness of in-domain representations in both supervised and self-supervised forms to solve the domain difference between remote sensing and the ImageNet dataset. The obtained weights from remote sensing images are utilized as initial weights for solving semantic segmentation and object detection tasks and state-of-the-art results are obtained. For self-supervised pre-training, we have utilized the SimSiam algorithm as it is simple and does not need huge computational resources. One of the most influential factors in acquiring general visual representations from remote sensing images is the pre-training dataset. To examine the effect of the pre-training dataset, equal-sized remote sensing datasets are used for pre-training. Our results have demonstrated that using datasets with a high spatial resolution for self-supervised representation learning leads to high performance in downstream tasks.