 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUAV Trajectory and Multi-User Beamforming Optimization for Clustered Users Against Passive Eavesdropping Attacks With Unknown CSI
Jun 13, 2023This paper tackles the fundamental passive eavesdropping problem in modern wireless communications in which the location and the channel state information (CSI) of the attackers are unknown. In this regard, we propose deploying an unmanned aerial vehicle (UAV) that serves as a mobile aerial relay (AR) to help ground base station (GBS) support a subset of vulnerable users. More precisely, our solution (1) clusters the single-antenna users in two groups to be either served by the GBS directly or via the AR, (2) employs optimal multi-user beamforming to the directly served users, and (3) optimizes the AR's 3D position, its multi-user beamforming matrix and transmit powers by combining closed-form solutions with machine learning techniques. Specifically, we design a plain beamforming and power optimization combined with a deep reinforcement learning (DRL) algorithm for an AR to optimize its trajectory for the security maximization of the served users. Numerical results show that the multi-user multiple input, single output (MU-MISO) system split between a GBS and an AR with optimized transmission parameters without knowledge of the eavesdropping channels achieves high secrecy capacities that scale well with increasing the number of users.
Aerial Base Station Positioning and Power Control for Securing Communications: A Deep Q-Network Approach
Dec 21, 2021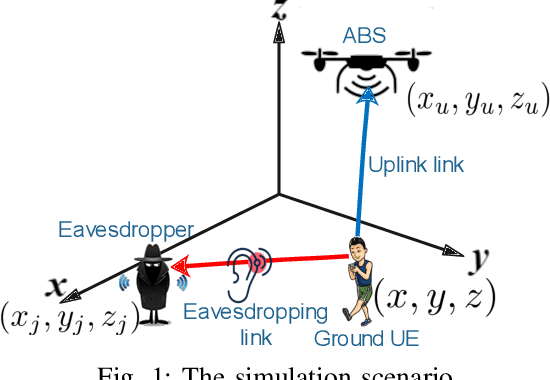

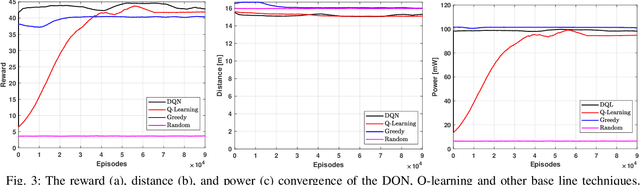
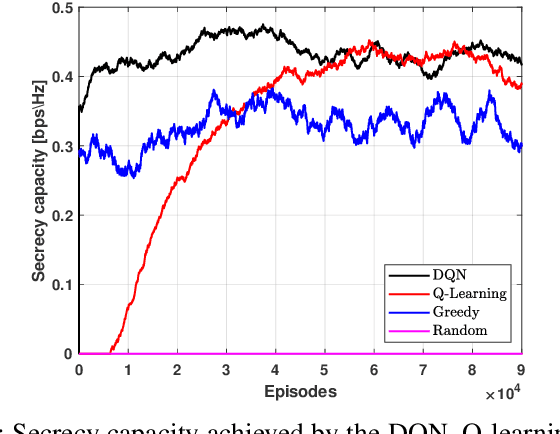
The unmanned aerial vehicle (UAV) is one of the technological breakthroughs that supports a variety of services, including communications. UAV will play a critical role in enhancing the physical layer security of wireless networks. This paper defines the problem of eavesdropping on the link between the ground user and the UAV, which serves as an aerial base station (ABS). The reinforcement learning algorithms Q-learning and deep Q-network (DQN) are proposed for optimizing the position of the ABS and the transmission power to enhance the data rate of the ground user. This increases the secrecy capacity without the system knowing the location of the eavesdropper. Simulation results show fast convergence and the highest secrecy capacity of the proposed DQN compared to Q-learning and baseline approaches.