 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefusal Beyond a Single Direction: A Preliminary Comparison of Diff-in-Means and INLP
Jun 11, 2026Arditi et al. (2024) has shown that refusal in safety fine-tuned chat models is mediated by a single linear direction in the residual stream, recoverable by a difference-in-means (DiM) of harmful and harmless activations. We compare DiM-based interventions (activation addition and directional ablation) with two interventions derived from Iterative Nullspace Projection (INLP) -- nullspace projection and counterfactual flipping -- on five open-weight chat models, asking whether INLP can match DiM at steering refusal and whether its richer parameterisation yields more tweakable interventions. INLP counterfactual flipping is competitive with DiM directional ablation on refusal suppression, while nullspace projection is consistently weaker. Restricting INLP to the leading directions of the extracted subspace preserves most of the suppression effect at near-baseline perplexity, giving a tunable capability. Geometrically, the two INLP interventions land in qualitatively different regions of activation space: nullspace projection collapses transformed activations \emph{between} the harmful and harmless clusters, while counterfactual flipping moves them into the opposite cluster, suggesting that the model encodes the absence of a concept differently from its opposite -- an intriguing distinction that warrants further investigation in future work.
How LLMs Follow Instructions: Skillful Coordination, Not a Universal Mechanism
Apr 07, 2026Instruction tuning is commonly assumed to endow language models with a domain-general ability to follow instructions, yet the underlying mechanism remains poorly understood. Does instruction-following rely on a universal mechanism or compositional skill deployment? We investigate this through diagnostic probing across nine diverse tasks in three instruction-tuned models. Our analysis provides converging evidence against a universal mechanism. First, general probes trained across all tasks consistently underperform task-specific specialists, indicating limited representational sharing. Second, cross-task transfer is weak and clustered by skill similarity. Third, causal ablation reveals sparse asymmetric dependencies rather than shared representations. Tasks also stratify by complexity across layers, with structural constraints emerging early and semantic tasks emerging late. Finally, temporal analysis shows constraint satisfaction operates as dynamic monitoring during generation rather than pre-generation planning. These findings indicate that instruction-following is better characterized as skillful coordination of diverse linguistic capabilities rather than deployment of a single abstract constraint-checking process.
Quid est VERITAS? A Modular Framework for Archival Document Analysis
Mar 30, 2026The digitisation of historical documents has traditionally been conceived as a process limited to character-level transcription, producing flat text that lacks the structural and semantic information necessary for substantive computational analysis. We present VERITAS (Vision-Enhanced Reading, Interpretation, and Transcription of Archival Sources), a modular, model-agnostic framework that reconceptualises digitisation as an integrated workflow encompassing transcription, layout analysis, and semantic enrichment. The pipeline is organised into four stages - Preprocessing, Extraction, Refinement, and Enrichment - and employs a schema-driven architecture that allows researchers to declaratively specify their extraction objectives. We evaluate VERITAS on the critical edition of Bernardino Corio's Storia di Milano, a Renaissance chronicle of over 1,600 pages. Results demonstrate that the pipeline achieves a 67.6% relative reduction in word error rate compared to a commercial OCR baseline, with a threefold reduction in end-to-end processing time when accounting for manual correction. We further illustrate the downstream utility of the pipeline's output by querying the transcribed corpus through a retrieval-augmented generation system, demonstrating its capacity to support historical inquiry.
Transcription and Recognition of Italian Parliamentary Speeches Using Vision-Language Models
Mar 30, 2026Parliamentary proceedings represent a rich yet challenging resource for computational analysis, particularly when preserved only as scanned historical documents. Existing efforts to transcribe Italian parliamentary speeches have relied on traditional Optical Character Recognition pipelines, resulting in transcription errors and limited semantic annotation. In this paper, we propose a pipeline based on Vision-Language Models for the automatic transcription, semantic segmentation, and entity linking of Italian parliamentary speeches. The pipeline employs a specialised OCR model to extract text while preserving reading order, followed by a large-scale Vision-Language Model that performs transcription refinement, element classification, and speaker identification by jointly reasoning over visual layout and textual content. Extracted speakers are then linked to the Chamber of Deputies knowledge base through SPARQL queries and a multi-strategy fuzzy matching procedure. Evaluation against an established benchmark demonstrates substantial improvements both in transcription quality and speaker tagging.
Unveiling Transformer Perception by Exploring Input Manifolds
Oct 08, 2024This paper introduces a general method for the exploration of equivalence classes in the input space of Transformer models. The proposed approach is based on sound mathematical theory which describes the internal layers of a Transformer architecture as sequential deformations of the input manifold. Using eigendecomposition of the pullback of the distance metric defined on the output space through the Jacobian of the model, we are able to reconstruct equivalence classes in the input space and navigate across them. We illustrate how this method can be used as a powerful tool for investigating how a Transformer sees the input space, facilitating local and task-agnostic explainability in Computer Vision and Natural Language Processing tasks.
LiMe: a Latin Corpus of Late Medieval Criminal Sentences
Apr 19, 2024The Latin language has received attention from the computational linguistics research community, which has built, over the years, several valuable resources, ranging from detailed annotated corpora to sophisticated tools for linguistic analysis. With the recent advent of large language models, researchers have also started developing models capable of generating vector representations of Latin texts. The performances of such models remain behind the ones for modern languages, given the disparity in available data. In this paper, we present the LiMe dataset, a corpus of 325 documents extracted from a series of medieval manuscripts called Libri sententiarum potestatis Mediolani, and thoroughly annotated by experts, in order to be employed for masked language model, as well as supervised natural language processing tasks.
How BERT Speaks Shakespearean English? Evaluating Historical Bias in Contextual Language Models
Feb 07, 2024In this paper, we explore the idea of analysing the historical bias of contextual language models based on BERT by measuring their adequacy with respect to Early Modern (EME) and Modern (ME) English. In our preliminary experiments, we perform fill-in-the-blank tests with 60 masked sentences (20 EME-specific, 20 ME-specific and 20 generic) and three different models (i.e., BERT Base, MacBERTh, English HLM). We then rate the model predictions according to a 5-point bipolar scale between the two language varieties and derive a weighted score to measure the adequacy of each model to EME and ME varieties of English.
Incremental Affinity Propagation based on Cluster Consolidation and Stratification
Jan 25, 2024Modern data mining applications require to perform incremental clustering over dynamic datasets by tracing temporal changes over the resulting clusters. In this paper, we propose A-Posteriori affinity Propagation (APP), an incremental extension of Affinity Propagation (AP) based on cluster consolidation and cluster stratification to achieve faithfulness and forgetfulness. APP enforces incremental clustering where i) new arriving objects are dynamically consolidated into previous clusters without the need to re-execute clustering over the entire dataset of objects, and ii) a faithful sequence of clustering results is produced and maintained over time, while allowing to forget obsolete clusters with decremental learning functionalities. Four popular labeled datasets are used to test the performance of APP with respect to benchmark clustering performances obtained by conventional AP and Incremental Affinity Propagation based on Nearest neighbor Assignment (IAPNA) algorithms. Experimental results show that APP achieves comparable clustering performance while enforcing scalability at the same time.
An Explainable Probabilistic Classifier for Categorical Data Inspired to Quantum Physics
May 26, 2021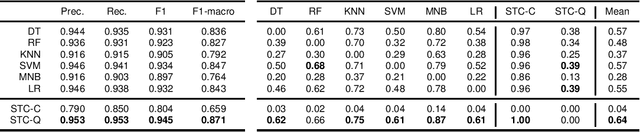

This paper presents Sparse Tensor Classifier (STC), a supervised classification algorithm for categorical data inspired by the notion of superposition of states in quantum physics. By regarding an observation as a superposition of features, we introduce the concept of wave-particle duality in machine learning and propose a generalized framework that unifies the classical and the quantum probability. We show that STC possesses a wide range of desirable properties not available in most other machine learning methods but it is at the same time exceptionally easy to comprehend and use. Empirical evaluation of STC on structured data and text classification demonstrates that our methodology achieves state-of-the-art performances compared to both standard classifiers and deep learning, at the additional benefit of requiring minimal data pre-processing and hyper-parameter tuning. Moreover, STC provides a native explanation of its predictions both for single instances and for each target label globally.