 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-characteristic Subject Selection from Biased Datasets
Dec 18, 2020

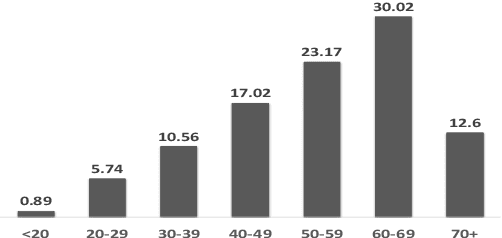

Subject selection plays a critical role in experimental studies, especially ones with human subjects. Anecdotal evidence suggests that many such studies, done at or near university campus settings suffer from selection bias, i.e., the too-many-college-kids-as-subjects problem. Unfortunately, traditional sampling techniques, when applied over biased data, will typically return biased results. In this paper, we tackle the problem of multi-characteristic subject selection from biased datasets. We present a constrained optimization-based method that finds the best possible sampling fractions for the different population subgroups, based on the desired sampling fractions provided by the researcher running the subject selection.We perform an extensive experimental study, using a variety of real datasets. Our results show that our proposed method outperforms the baselines for all problem variations by up to 90%.
hood2vec: Identifying Similar Urban Areas Using Mobility Networks
Jul 17, 2019
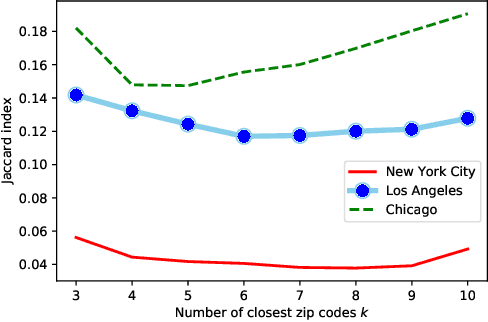

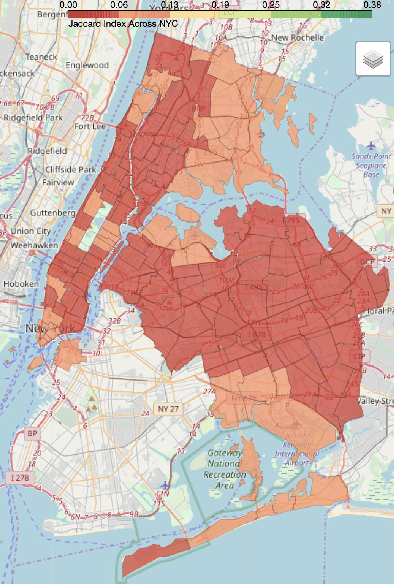
Which area in NYC is the most similar to Lower East Side? What about the NoHo Arts District in Los Angeles? Traditionally this task utilizes information about the type of places located within the areas and some popularity/quality metric. We take a different approach. In particular, urban dwellers' time-variant mobility is a reflection of how they interact with their city over time. Hence, in this paper, we introduce an approach, namely hood2vec, to identify the similarity between urban areas through learning a node embedding of the mobility network captured through Foursquare check-ins. We compare the pairwise similarities obtained from hood2vec with the ones obtained from comparing the types of venues in the different areas. The low correlation between the two indicates that the mobility dynamics and the venue types potentially capture different aspects of similarity between urban areas.