 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilabel 12-Lead Electrocardiogram Classification Using Gradient Boosting Tree Ensemble
Oct 21, 2020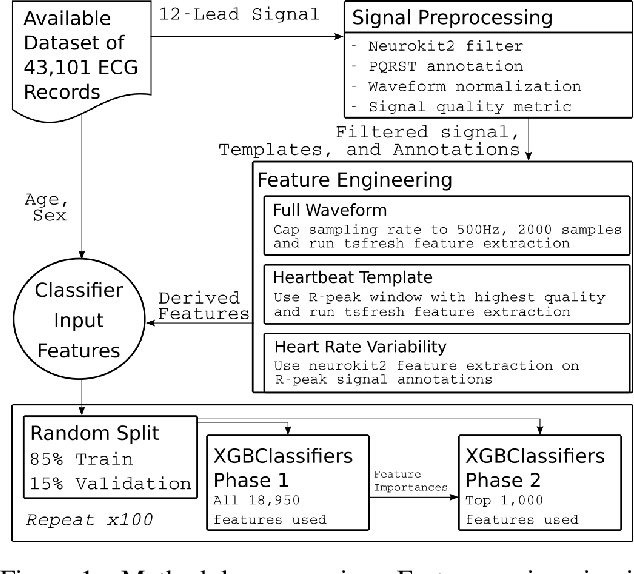
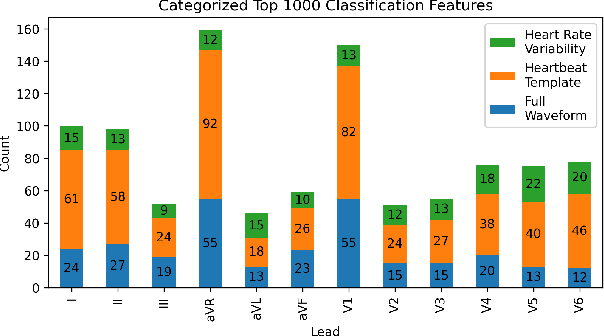
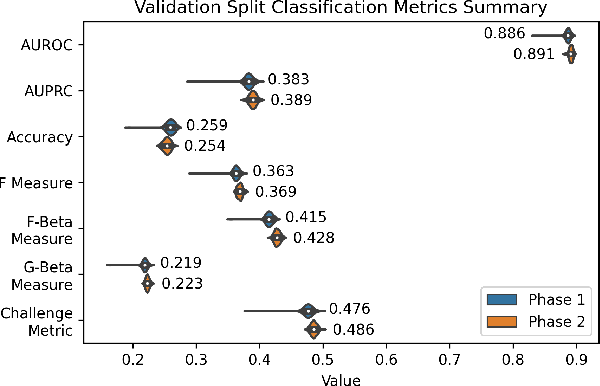
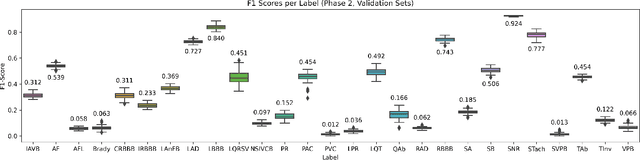
The 12-lead electrocardiogram (ECG) is a commonly used tool for detecting cardiac abnormalities such as atrial fibrillation, blocks, and irregular complexes. For the PhysioNet/CinC 2020 Challenge, we built an algorithm using gradient boosted tree ensembles fitted on morphology and signal processing features to classify ECG diagnosis. For each lead, we derive features from heart rate variability, PQRST template shape, and the full signal waveform. We join the features of all 12 leads to fit an ensemble of gradient boosting decision trees to predict probabilities of ECG instances belonging to each class. We train a phase one set of feature importance determining models to isolate the top 1,000 most important features to use in our phase two diagnosis prediction models. We use repeated random sub-sampling by splitting our dataset of 43,101 records into 100 independent runs of 85:15 training/validation splits for our internal evaluation results. Our methodology generates us an official phase validation set score of 0.476 and test set score of -0.080 under the team name, CVC, placing us 36 out of 41 in the rankings.
Tracing Forum Posts to MOOC Content using Topic Analysis
Apr 15, 2019
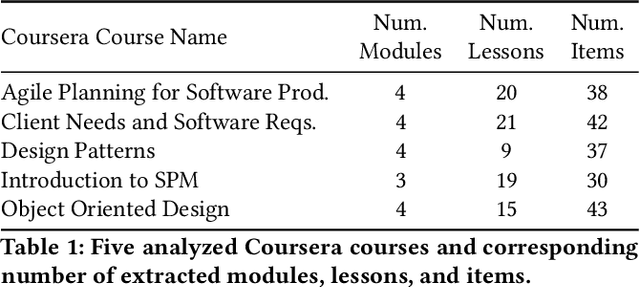
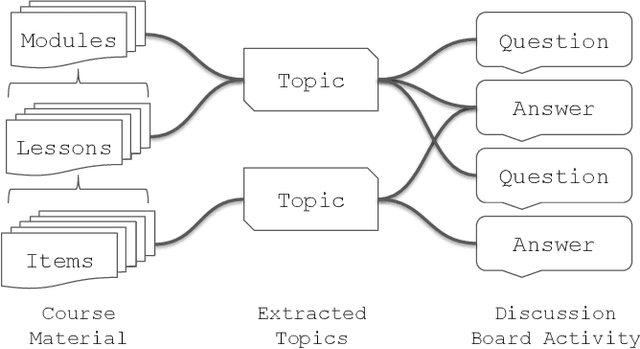

Massive Open Online Courses are educational programs that are open and accessible to a large number of people through the internet. To facilitate learning, MOOC discussion forums exist where students and instructors communicate questions, answers, and thoughts related to the course. The primary objective of this paper is to investigate tracing discussion forum posts back to course lecture videos and readings using topic analysis. We utilize both unsupervised and supervised variants of Latent Dirichlet Allocation (LDA) to extract topics from course material and classify forum posts. We validate our approach on posts bootstrapped from five Coursera courses and determine that topic models can be used to map student discussion posts back to the underlying course lecture or reading. Labeled LDA outperforms unsupervised Hierarchical Dirichlet Process LDA and base LDA for our traceability task. This research is useful as it provides an automated approach for clustering student discussions by course material, enabling instructors to quickly evaluate student misunderstanding of content and clarify materials accordingly.