 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Video Compression With Deep Visual-Attention Models
Mar 19, 2019
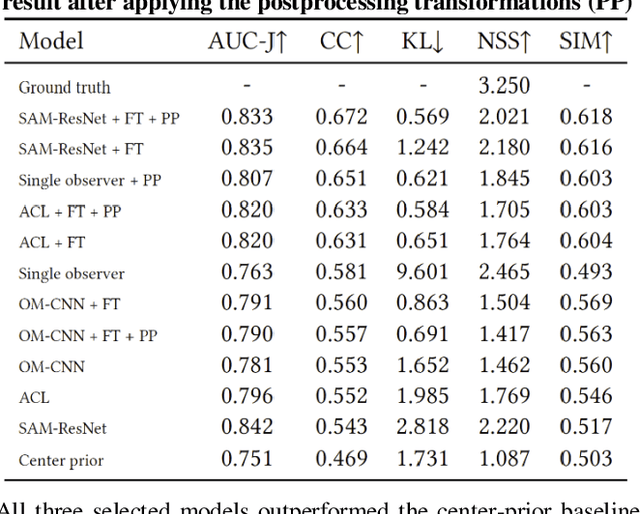


Recent advances in deep learning have markedly improved the quality of visual-attention modelling. In this work we apply these advances to video compression. We propose a compression method that uses a saliency model to adaptively compress frame areas in accordance with their predicted saliency. We selected three state-of-the-art saliency models, adapted them for video compression and analyzed their results. The analysis includes objective evaluation of the models as well as objective and subjective evaluation of the compressed videos. Our method, which is based on the x264 video codec, can produce videos with the same visual quality as regular x264, but it reduces the bitrate by 25% according to the objective evaluation and by 17% according to the subjective one. Also, both the subjective and objective evaluations demonstrate that saliency models can compete with gaze maps for a single observer. Our method can extend to most video bitstream formats and can improve video compression quality without requiring a switch to a new video encoding standard.