 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Diversify for Product Question Generation
Jul 06, 2022
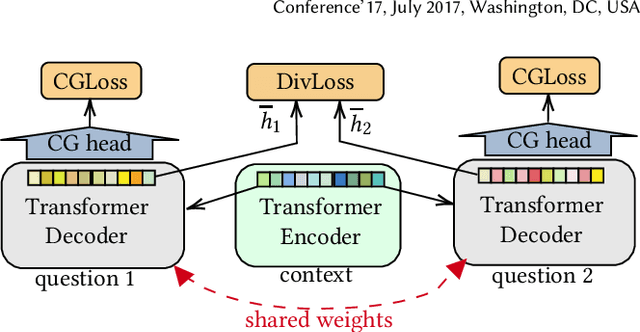

We address the product question generation task. For a given product description, our goal is to generate questions that reflect potential user information needs that are either missing or not well covered in the description. Moreover, we wish to cover diverse user information needs that may span a multitude of product types. To this end, we first show how the T5 pre-trained Transformer encoder-decoder model can be fine-tuned for the task. Yet, while the T5 generated questions have a reasonable quality compared to the state-of-the-art method for the task (KPCNet), many of such questions are still too general, resulting in a sub-optimal global question diversity. As an alternative, we propose a novel learning-to-diversify (LTD) fine-tuning approach that allows to enrich the language learned by the underlying Transformer model. Our empirical evaluation shows that, using our approach significantly improves the global diversity of the underlying Transformer model, while preserves, as much as possible, its generation relevance.
Sequential Modeling with Multiple Attributes for Watchlist Recommendation in E-Commerce
Oct 24, 2021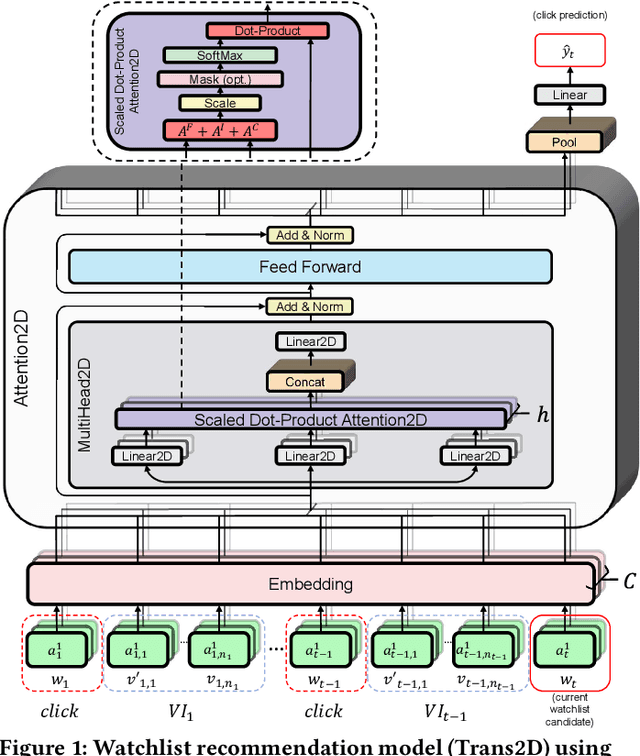
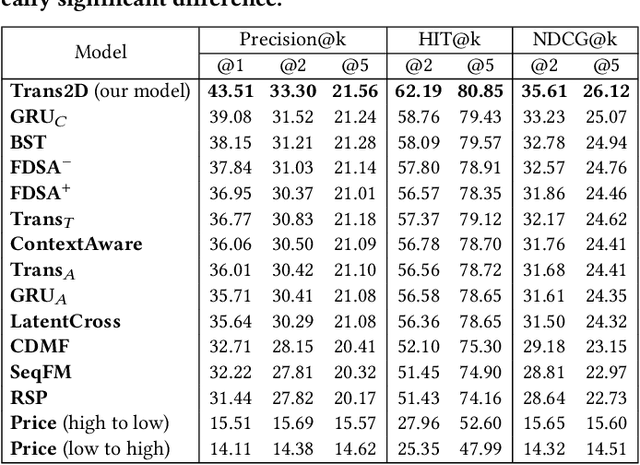

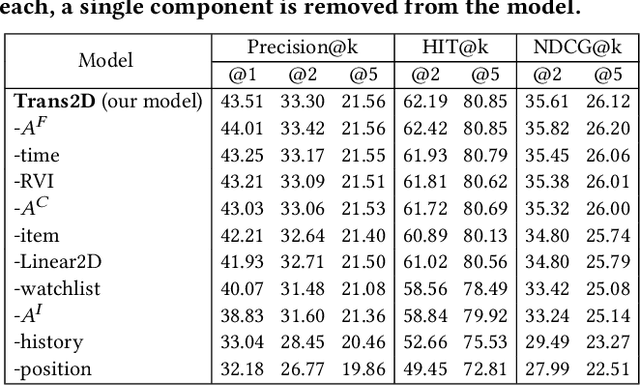
In e-commerce, the watchlist enables users to track items over time and has emerged as a primary feature, playing an important role in users' shopping journey. Watchlist items typically have multiple attributes whose values may change over time (e.g., price, quantity). Since many users accumulate dozens of items on their watchlist, and since shopping intents change over time, recommending the top watchlist items in a given context can be valuable. In this work, we study the watchlist functionality in e-commerce and introduce a novel watchlist recommendation task. Our goal is to prioritize which watchlist items the user should pay attention to next by predicting the next items the user will click. We cast this task as a specialized sequential recommendation task and discuss its characteristics. Our proposed recommendation model, Trans2D, is built on top of the Transformer architecture, where we further suggest a novel extended attention mechanism (Attention2D) that allows to learn complex item-item, attribute-attribute and item-attribute patterns from sequential-data with multiple item attributes. Using a large-scale watchlist dataset from eBay, we evaluate our proposed model, where we demonstrate its superiority compared to multiple state-of-the-art baselines, many of which are adapted for this task.
E-Commerce Dispute Resolution Prediction
Oct 13, 2021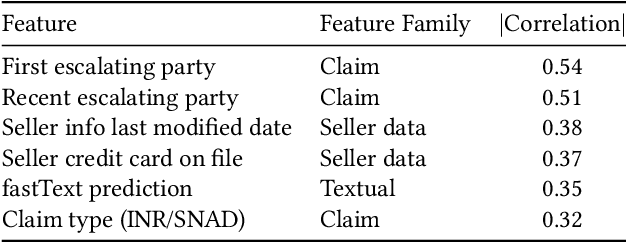
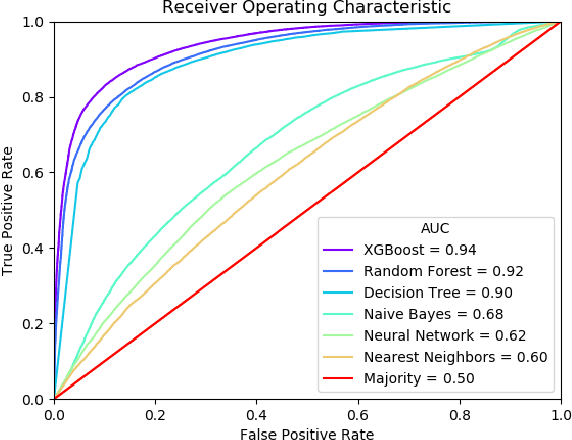
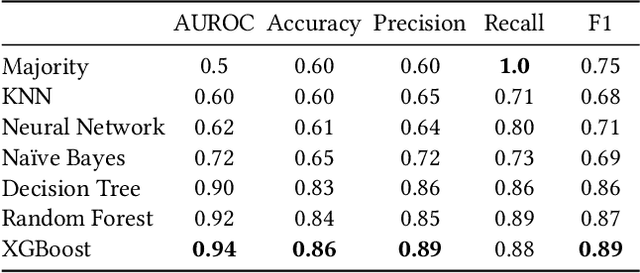

E-Commerce marketplaces support millions of daily transactions, and some disagreements between buyers and sellers are unavoidable. Resolving disputes in an accurate, fast, and fair manner is of great importance for maintaining a trustworthy platform. Simple cases can be automated, but intricate cases are not sufficiently addressed by hard-coded rules, and therefore most disputes are currently resolved by people. In this work we take a first step towards automatically assisting human agents in dispute resolution at scale. We construct a large dataset of disputes from the eBay online marketplace, and identify several interesting behavioral and linguistic patterns. We then train classifiers to predict dispute outcomes with high accuracy. We explore the model and the dataset, reporting interesting correlations, important features, and insights.
PreSizE: Predicting Size in E-Commerce using Transformers
May 04, 2021
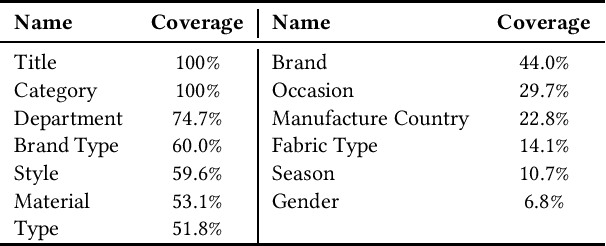
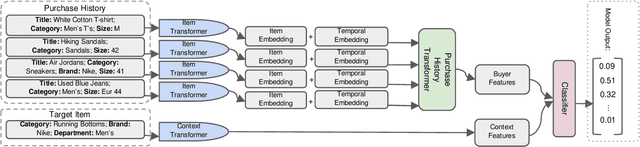
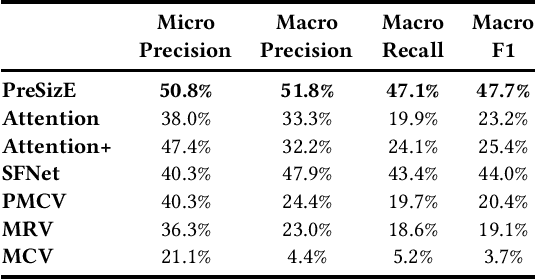
Recent advances in the e-commerce fashion industry have led to an exploration of novel ways to enhance buyer experience via improved personalization. Predicting a proper size for an item to recommend is an important personalization challenge, and is being studied in this work. Earlier works in this field either focused on modeling explicit buyer fitment feedback or modeling of only a single aspect of the problem (e.g., specific category, brand, etc.). More recent works proposed richer models, either content-based or sequence-based, better accounting for content-based aspects of the problem or better modeling the buyer's online journey. However, both these approaches fail in certain scenarios: either when encountering unseen items (sequence-based models) or when encountering new users (content-based models). To address the aforementioned gaps, we propose PreSizE - a novel deep learning framework which utilizes Transformers for accurate size prediction. PreSizE models the effect of both content-based attributes, such as brand and category, and the buyer's purchase history on her size preferences. Using an extensive set of experiments on a large-scale e-commerce dataset, we demonstrate that PreSizE is capable of achieving superior prediction performance compared to previous state-of-the-art baselines. By encoding item attributes, PreSizE better handles cold-start cases with unseen items, and cases where buyers have little past purchase data. As a proof of concept, we demonstrate that size predictions made by PreSizE can be effectively integrated into an existing production recommender system yielding very effective features and significantly improving recommendations.