 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirearm Detection via Convolutional Neural Networks: Comparing a Semantic Segmentation Model Against End-to-End Solutions
Dec 17, 2020

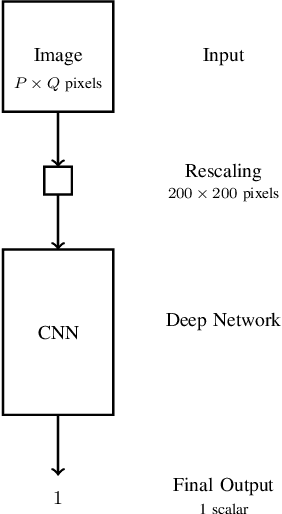

Threat detection of weapons and aggressive behavior from live video can be used for rapid detection and prevention of potentially deadly incidents such as terrorism, general criminal offences, or even domestic violence. One way for achieving this is through the use of artificial intelligence and, in particular, machine learning for image analysis. In this paper we conduct a comparison between a traditional monolithic end-to-end deep learning model and a previously proposed model based on an ensemble of simpler neural networks detecting fire-weapons via semantic segmentation. We evaluated both models from different points of view, including accuracy, computational and data complexity, flexibility and reliability. Our results show that a semantic segmentation model provides considerable amount of flexibility and resilience in the low data environment compared to classical deep model models, although its configuration and tuning presents a challenge in achieving the same levels of accuracy as an end-to-end model.
Firearm Detection and Segmentation Using an Ensemble of Semantic Neural Networks
Feb 11, 2020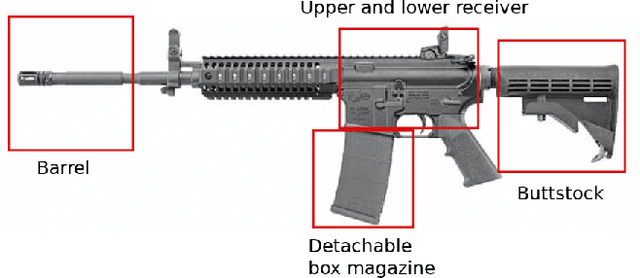



In recent years we have seen an upsurge in terror attacks around the world. Such attacks usually happen in public places with large crowds to cause the most damage possible and get the most attention. Even though surveillance cameras are assumed to be a powerful tool, their effect in preventing crime is far from clear due to either limitation in the ability of humans to vigilantly monitor video surveillance or for the simple reason that they are operating passively. In this paper, we present a weapon detection system based on an ensemble of semantic Convolutional Neural Networks that decomposes the problem of detecting and locating a weapon into a set of smaller problems concerned with the individual component parts of a weapon. This approach has computational and practical advantages: a set of simpler neural networks dedicated to specific tasks requires less computational resources and can be trained in parallel; the overall output of the system given by the aggregation of the outputs of individual networks can be tuned by a user to trade-off false positives and false negatives; finally, according to ensemble theory, the output of the overall system will be robust and reliable even in the presence of weak individual models. We evaluated our system running simulations aimed at assessing the accuracy of individual networks and the whole system. The results on synthetic data and real-world data are promising, and they suggest that our approach may have advantages compared to the monolithic approach based on a single deep convolutional neural network.