 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIReAD: Simple Method for Learning High-quality Representations from Scientific Documents
May 07, 2023Learning semantically meaningful representations from scientific documents can facilitate academic literature search and improve performance of recommendation systems. Pre-trained language models have been shown to learn rich textual representations, yet they cannot provide powerful document-level representations for scientific articles. We propose MIReAD, a simple method that learns high-quality representations of scientific papers by fine-tuning transformer model to predict the target journal class based on the abstract. We train MIReAD on more than 500,000 PubMed and arXiv abstracts across over 2,000 journal classes. We show that MIReAD produces representations that can be used for similar papers retrieval, topic categorization and literature search. Our proposed approach outperforms six existing models for representation learning on scientific documents across four evaluation standards.
Learning multi-scale functional representations of proteins from single-cell microscopy data
May 24, 2022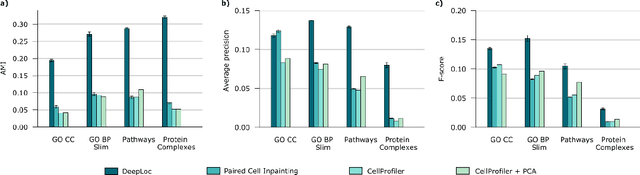
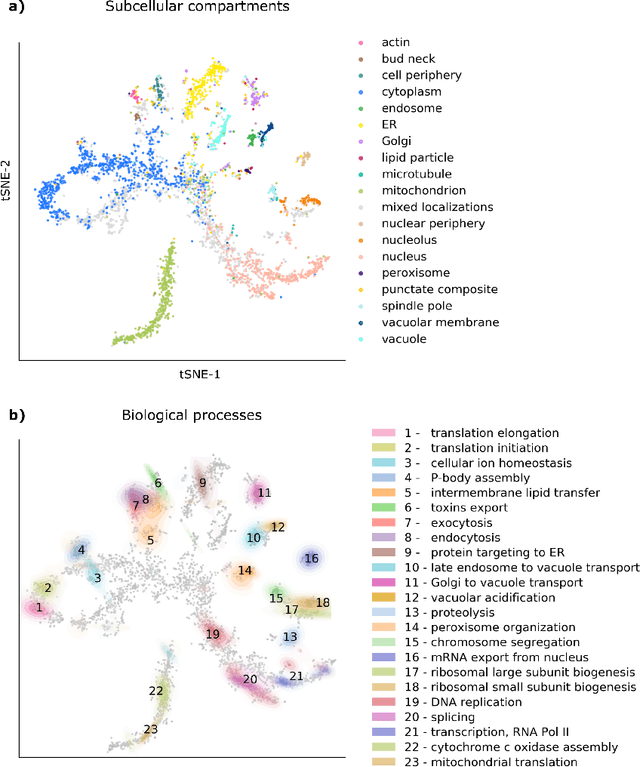
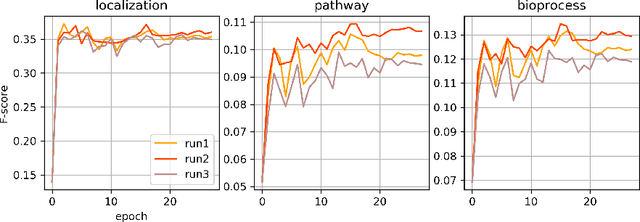
Protein function is inherently linked to its localization within the cell, and fluorescent microscopy data is an indispensable resource for learning representations of proteins. Despite major developments in molecular representation learning, extracting functional information from biological images remains a non-trivial computational task. Current state-of-the-art approaches use autoencoder models to learn high-quality features by reconstructing images. However, such methods are prone to capturing noise and imaging artifacts. In this work, we revisit deep learning models used for classifying major subcellular localizations, and evaluate representations extracted from their final layers. We show that simple convolutional networks trained on localization classification can learn protein representations that encapsulate diverse functional information, and significantly outperform autoencoder-based models. We also propose a robust evaluation strategy to assess quality of protein representations across different scales of biological function.