 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-based Entity Legal Form Classification
Oct 19, 2023



We propose the application of Transformer-based language models for classifying entity legal forms from raw legal entity names. Specifically, we employ various BERT variants and compare their performance against multiple traditional baselines. Our evaluation encompasses a substantial subset of freely available Legal Entity Identifier (LEI) data, comprising over 1.1 million legal entities from 30 different legal jurisdictions. The ground truth labels for classification per jurisdiction are taken from the Entity Legal Form (ELF) code standard (ISO 20275). Our findings demonstrate that pre-trained BERT variants outperform traditional text classification approaches in terms of F1 score, while also performing comparably well in the Macro F1 Score. Moreover, the validity of our proposal is supported by the outcome of third-party expert reviews conducted in ten selected jurisdictions. This study highlights the significant potential of Transformer-based models in advancing data standardization and data integration. The presented approaches can greatly benefit financial institutions, corporations, governments and other organizations in assessing business relationships, understanding risk exposure, and promoting effective governance.
Neural Networks and Value at Risk
May 06, 2020
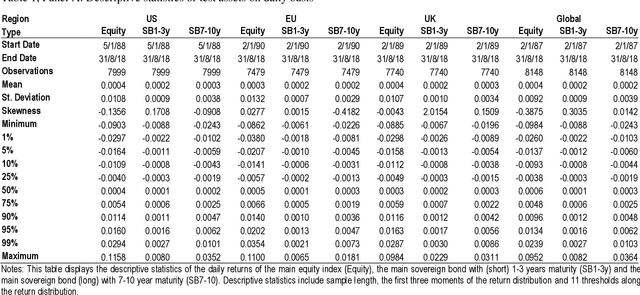
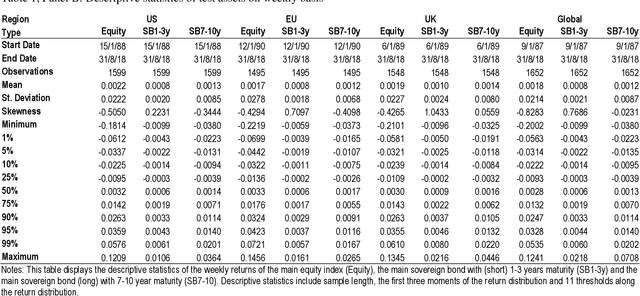
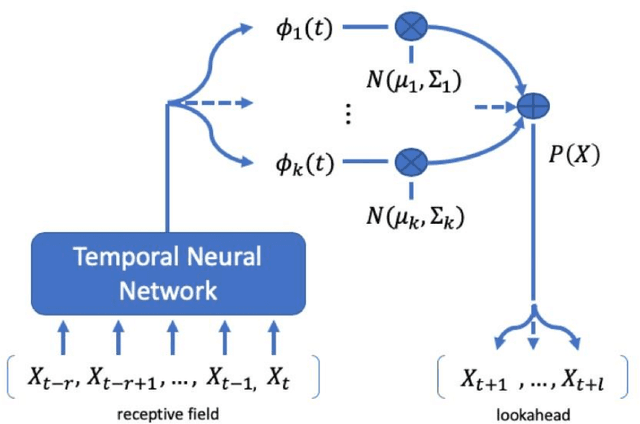
Utilizing a generative regime switching framework, we perform Monte-Carlo simulations of asset returns for Value at Risk threshold estimation. Using equity markets and long term bonds as test assets in the global, US, Euro area and UK setting over an up to 1,250 weeks sample horizon ending in August 2018, we investigate neural networks along three design steps relating (i) to the initialization of the neural network, (ii) its incentive function according to which it has been trained and (iii) the amount of data we feed. First, we compare neural networks with random seeding with networks that are initialized via estimations from the best-established model (i.e. the Hidden Markov). We find latter to outperform in terms of the frequency of VaR breaches (i.e. the realized return falling short of the estimated VaR threshold). Second, we balance the incentive structure of the loss function of our networks by adding a second objective to the training instructions so that the neural networks optimize for accuracy while also aiming to stay in empirically realistic regime distributions (i.e. bull vs. bear market frequencies). In particular this design feature enables the balanced incentive recurrent neural network (RNN) to outperform the single incentive RNN as well as any other neural network or established approach by statistically and economically significant levels. Third, we half our training data set of 2,000 days. We find our networks when fed with substantially less data (i.e. 1,000 days) to perform significantly worse which highlights a crucial weakness of neural networks in their dependence on very large data sets ...