 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking and Exploring the Capabilities of LLMs for Attack Investigations
Jun 09, 2026This paper presents AuditBench, a new benchmark dataset for evaluating the capabilities of LLMs at investigating security-related system audit logs. We design and use this benchmark to explore the performance of LLMs on four log-investigation tasks that incident response teams commonly perform, ranging from triaging alerts generated by detectors to identifying persistence mechanisms on compromised systems. AuditBench consists of system audit logs collected from Linux and Windows machines, and spans over 50 different security investigation scenarios, including both malicious and benign activity. Using our benchmark, we evaluate and analyze the performance of five frontier LLMs at analyzing audit logs for attack investigations. Our analysis illuminates how LLM performance and error profiles vary according to different design choices, such as differences in model size, data representation, prompt construction, and specific investigation tasks. Additionally, we characterize the quality of the explanations produced by LLMs and the types of errors that models make across our benchmark. Collectively, our work provides a foundation for assessing the capabilities of LLMs for investigating security logs, novel insights for practitioners using LLMs in security operations, and important directions for future research.
Fine Grained Insider Risk Detection
Nov 04, 2024
We present a method to detect departures from business-justified workflows among support agents. Our goal is to assist auditors in identifying agent actions that cannot be explained by the activity within their surrounding context, where normal activity patterns are established from historical data. We apply our method to help audit millions of actions of over three thousand support agents. We collect logs from the tools used by support agents and construct a bipartite graph of Actions and Entities representing all the actions of the agents, as well as background information about entities. From this graph, we sample subgraphs rooted on security-significant actions taken by the agents. Each subgraph captures the relevant context of the root action in terms of other actions, entities and their relationships. We then prioritize the rooted-subgraphs for auditor review using feed-forward and graph neural networks, as well as nearest neighbors techniques. To alleviate the issue of scarce labeling data, we use contrastive learning and domain-specific data augmentations. Expert auditors label the top ranked subgraphs as ``worth auditing" or ``not worth auditing" based on the company's business policies. This system finds subgraphs that are worth auditing with high enough precision to be used in production.
Evasion and Hardening of Tree Ensemble Classifiers
May 27, 2016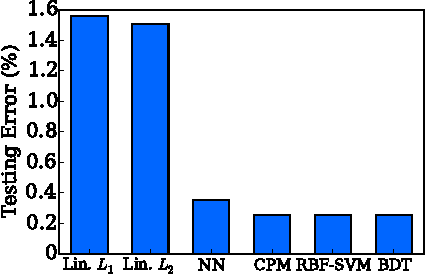
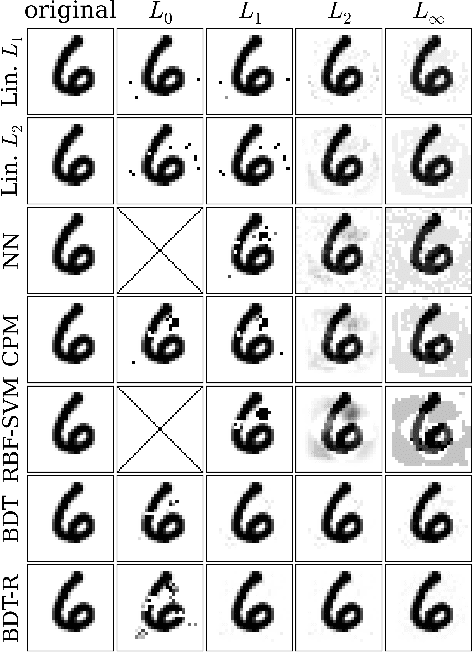
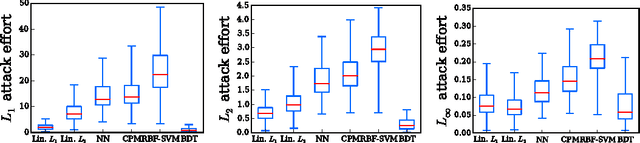
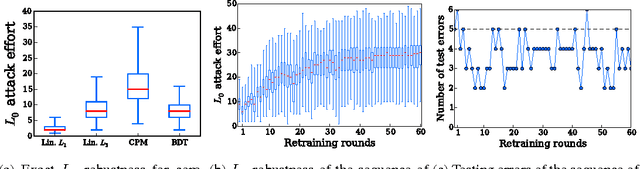
Classifier evasion consists in finding for a given instance $x$ the nearest instance $x'$ such that the classifier predictions of $x$ and $x'$ are different. We present two novel algorithms for systematically computing evasions for tree ensembles such as boosted trees and random forests. Our first algorithm uses a Mixed Integer Linear Program solver and finds the optimal evading instance under an expressive set of constraints. Our second algorithm trades off optimality for speed by using symbolic prediction, a novel algorithm for fast finite differences on tree ensembles. On a digit recognition task, we demonstrate that both gradient boosted trees and random forests are extremely susceptible to evasions. Finally, we harden a boosted tree model without loss of predictive accuracy by augmenting the training set of each boosting round with evading instances, a technique we call adversarial boosting.