 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeak Kerr Nonlinearity Boosts the Performance of Frequency-Multiplexed Photonic Extreme Learning Machines: A Multifaceted Approach
Dec 19, 2023We provide a theoretical, numerical, and experimental investigation of the Kerr nonlinearity impact on the performance of a frequency-multiplexed Extreme Learning Machine (ELM). In such ELM, the neuron signals are encoded in the lines of a frequency comb. The Kerr nonlinearity facilitates the randomized neuron connections allowing for efficient information mixing. A programmable spectral filter applies the output weights. The system operates in a continuous-wave regime. Even at low input peak powers, the resulting weak Kerr nonlinearity is sufficient to significantly boost the performance on several tasks. This boost already arises when one uses only the very small Kerr nonlinearity present in a 20-meter long erbium-doped fiber amplifier. In contrast, a subsequent propagation in 540 meters of a single-mode fiber improves the performance only slightly, whereas additional information mixing with a phase modulator does not result in a further improvement at all. We introduce a model to show that, in frequency-multiplexed ELMs, the Kerr nonlinearity mixes information via four-wave mixing, rather than via self- or cross-phase modulation. At low powers, this effect is quartic in the comb-line amplitudes. Numerical simulations validate our experimental results and interpretation.
Deep Photonic Reservoir Computer for Speech Recognition
Dec 11, 2023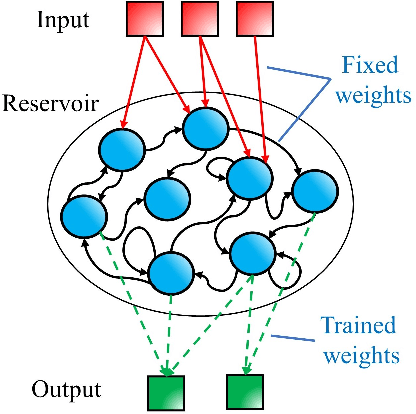
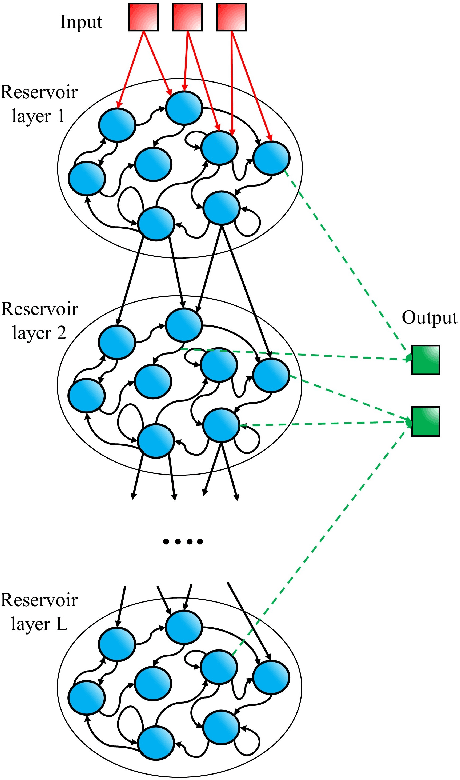
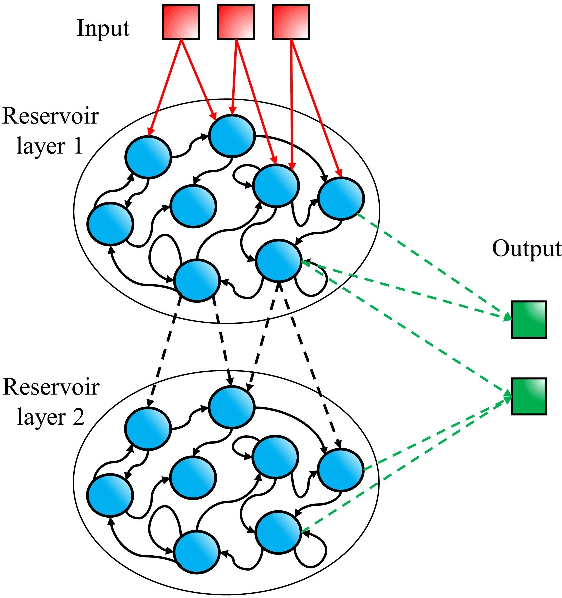
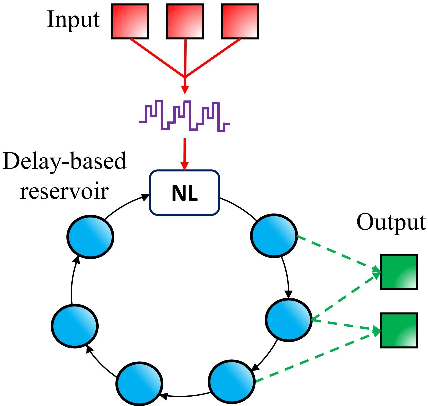
Speech recognition is a critical task in the field of artificial intelligence and has witnessed remarkable advancements thanks to large and complex neural networks, whose training process typically requires massive amounts of labeled data and computationally intensive operations. An alternative paradigm, reservoir computing, is energy efficient and is well adapted to implementation in physical substrates, but exhibits limitations in performance when compared to more resource-intensive machine learning algorithms. In this work we address this challenge by investigating different architectures of interconnected reservoirs, all falling under the umbrella of deep reservoir computing. We propose a photonic-based deep reservoir computer and evaluate its effectiveness on different speech recognition tasks. We show specific design choices that aim to simplify the practical implementation of a reservoir computer while simultaneously achieving high-speed processing of high-dimensional audio signals. Overall, with the present work we hope to help the advancement of low-power and high-performance neuromorphic hardware.