 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-to-LaTeX Converter for Mathematical Formulas and Text
Aug 07, 2024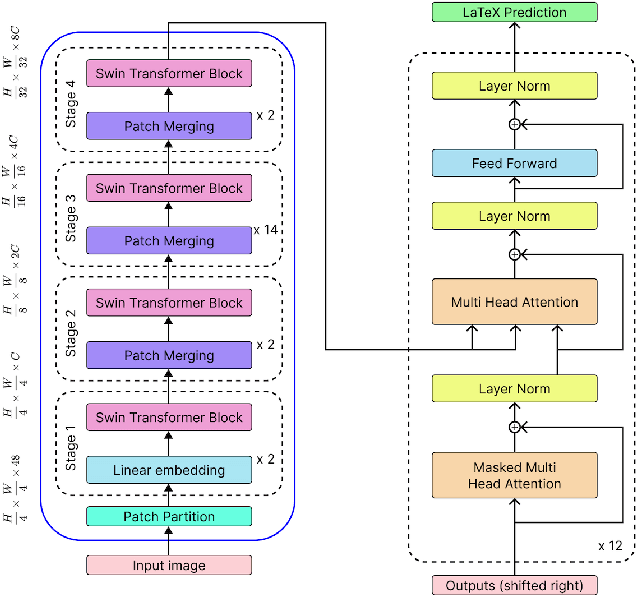
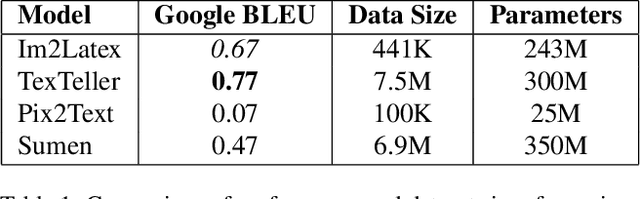
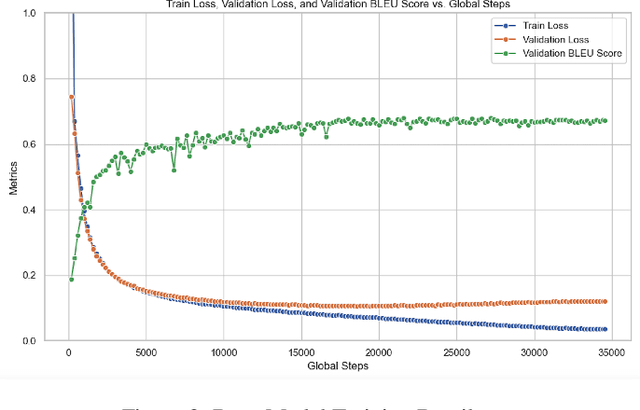
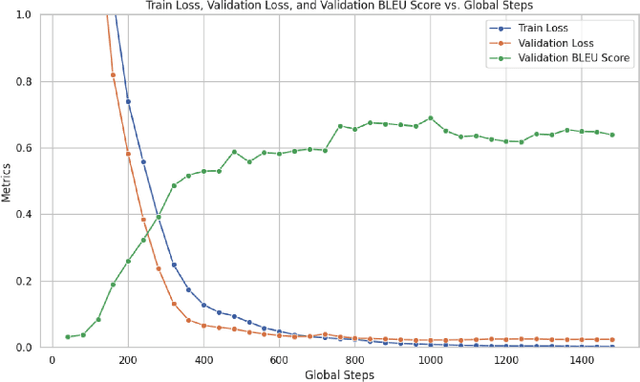
In this project, we train a vision encoder-decoder model to generate LaTeX code from images of mathematical formulas and text. Utilizing a diverse collection of image-to-LaTeX data, we build two models: a base model with a Swin Transformer encoder and a GPT-2 decoder, trained on machine-generated images, and a fine-tuned version enhanced with Low-Rank Adaptation (LoRA) trained on handwritten formulas. We then compare the BLEU performance of our specialized model on a handwritten test set with other similar models, such as Pix2Text, TexTeller, and Sumen. Through this project, we contribute open-source models for converting images to LaTeX and provide from-scratch code for building these models with distributed training and GPU optimizations.