 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLPlatt: Simple Calibration Framework for Ranking Models
Jan 13, 2026Ranking models are extensively used in e-commerce for relevance estimation. These models often suffer from poor interpretability and no scale calibration, particularly when trained with typical ranking loss functions. This paper addresses the problem of post-hoc calibration of ranking models. We introduce MLPlatt: a simple yet effective ranking model calibration method that preserves the item ordering and converts ranker outputs to interpretable click-through rate (CTR) probabilities usable in downstream tasks. The method is context-aware by design and achieves good calibration metrics globally, and within strata corresponding to different values of a selected categorical field (such as user country or device), which is often important from a business perspective of an E-commerce platform. We demonstrate the superiority of MLPlatt over existing approaches on two datasets, achieving an improvement of over 10\% in F-ECE (Field Expected Calibration Error) compared to other methods. Most importantly, we show that high-quality calibration can be achieved without compromising the ranking quality.
PLLuM: A Family of Polish Large Language Models
Nov 05, 2025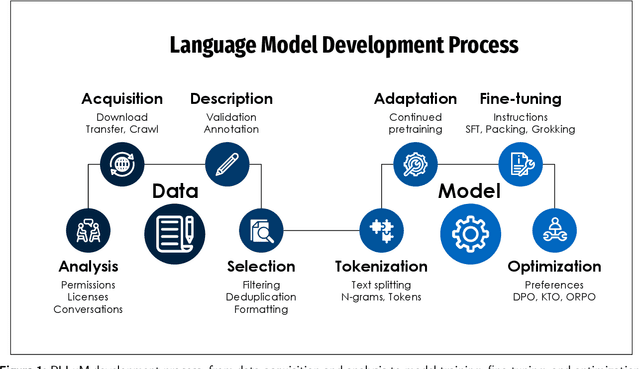
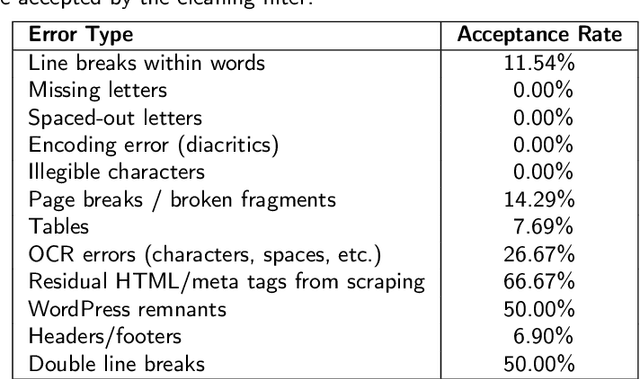
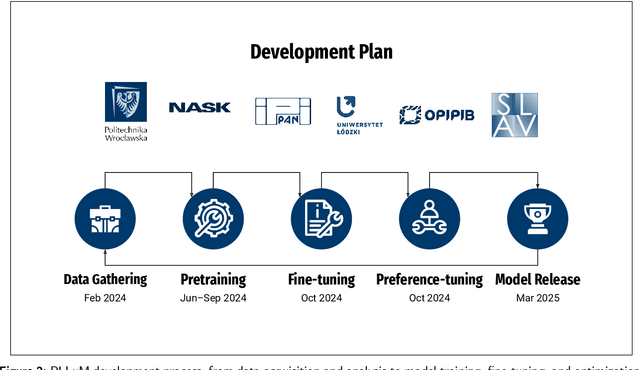

Large Language Models (LLMs) play a central role in modern artificial intelligence, yet their development has been primarily focused on English, resulting in limited support for other languages. We present PLLuM (Polish Large Language Model), the largest open-source family of foundation models tailored specifically for the Polish language. Developed by a consortium of major Polish research institutions, PLLuM addresses the need for high-quality, transparent, and culturally relevant language models beyond the English-centric commercial landscape. We describe the development process, including the construction of a new 140-billion-token Polish text corpus for pre-training, a 77k custom instructions dataset, and a 100k preference optimization dataset. A key component is a Responsible AI framework that incorporates strict data governance and a hybrid module for output correction and safety filtering. We detail the models' architecture, training procedures, and alignment techniques for both base and instruction-tuned variants, and demonstrate their utility in a downstream task within public administration. By releasing these models publicly, PLLuM aims to foster open research and strengthen sovereign AI technologies in Poland.
Improving Domain-Specific Retrieval by NLI Fine-Tuning
Aug 06, 2023The aim of this article is to investigate the fine-tuning potential of natural language inference (NLI) data to improve information retrieval and ranking. We demonstrate this for both English and Polish languages, using data from one of the largest Polish e-commerce sites and selected open-domain datasets. We employ both monolingual and multilingual sentence encoders fine-tuned by a supervised method utilizing contrastive loss and NLI data. Our results point to the fact that NLI fine-tuning increases the performance of the models in both tasks and both languages, with the potential to improve mono- and multilingual models. Finally, we investigate uniformity and alignment of the embeddings to explain the effect of NLI-based fine-tuning for an out-of-domain use-case.
SAMSum Corpus: A Human-annotated Dialogue Dataset for Abstractive Summarization
Nov 29, 2019

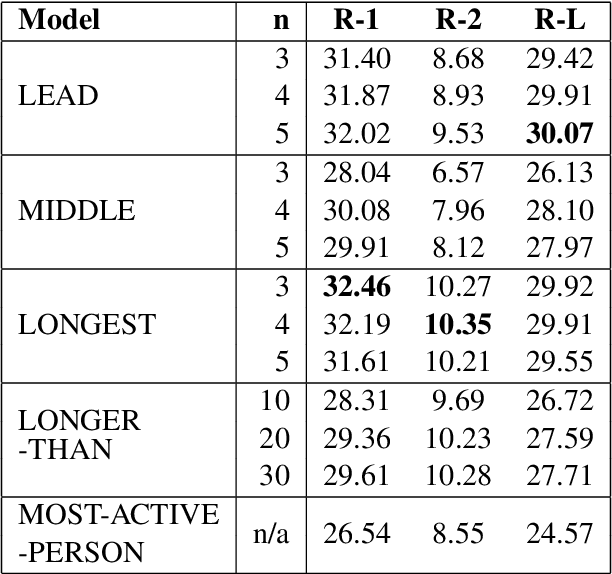
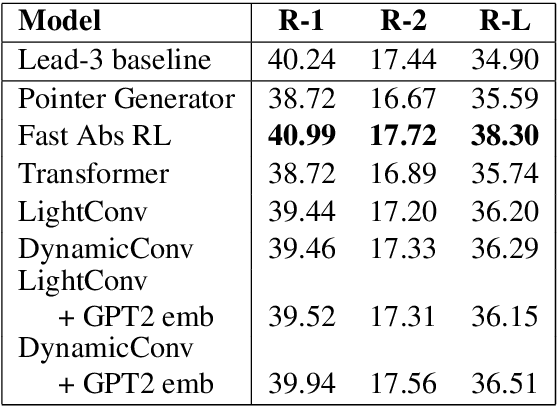
This paper introduces the SAMSum Corpus, a new dataset with abstractive dialogue summaries. We investigate the challenges it poses for automated summarization by testing several models and comparing their results with those obtained on a corpus of news articles. We show that model-generated summaries of dialogues achieve higher ROUGE scores than the model-generated summaries of news -- in contrast with human evaluators' judgement. This suggests that a challenging task of abstractive dialogue summarization requires dedicated models and non-standard quality measures. To our knowledge, our study is the first attempt to introduce a high-quality chat-dialogues corpus, manually annotated with abstractive summarizations, which can be used by the research community for further studies.
* Attachment contains the described dataset archived in 7z format. Please see the attached readme and licence. Update of the previous version: changed formats of train/val/test files in corpus.7z
TMLab SRPOL at SemEval-2019 Task 8: Fact Checking in Community Question Answering Forums
May 29, 2019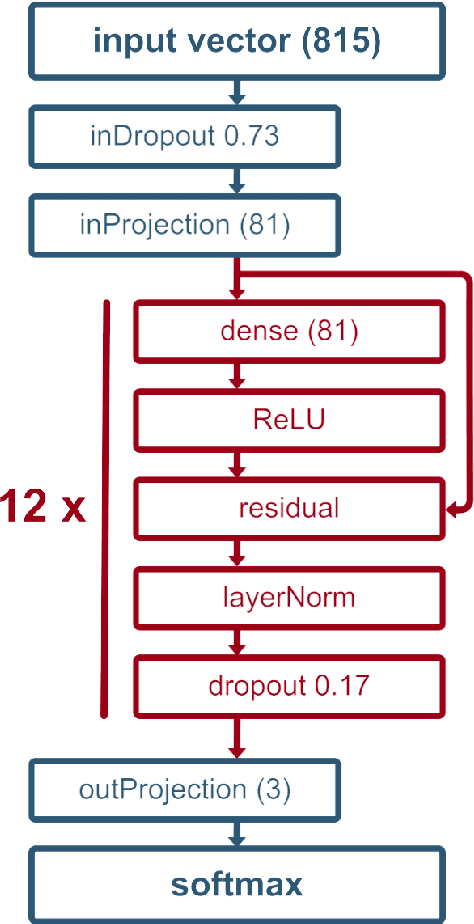

The article describes our submission to SemEval 2019 Task 8 on Fact-Checking in Community Forums. The systems under discussion participated in Subtask A: decide whether a question asks for factual information, opinion/advice or is just socializing. Our primary submission was ranked as the second one among all participants in the official evaluation phase. The article presents our primary solution: Deeply Regularized Residual Neural Network (DRR NN) with Universal Sentence Encoder embeddings. This is followed by a description of two contrastive solutions based on ensemble methods.