 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexical Access Model for Italian -- Modeling human speech processing: identification of words in running speech toward lexical access based on the detection of landmarks and other acoustic cues to features
Jun 24, 2021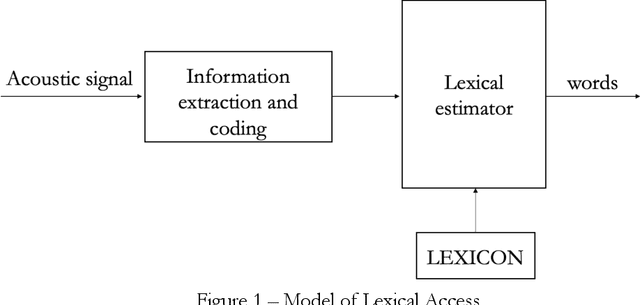
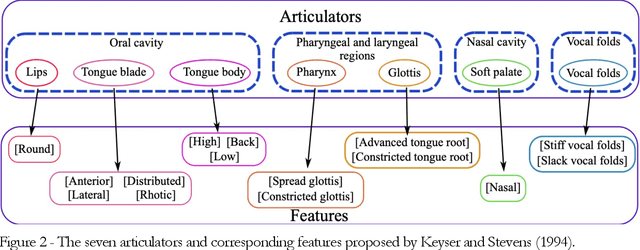


Modelling the process that a listener actuates in deriving the words intended by a speaker requires setting a hypothesis on how lexical items are stored in memory. This work aims at developing a system that imitates humans when identifying words in running speech and, in this way, provide a framework to better understand human speech processing. We build a speech recognizer for Italian based on the principles of Stevens' model of Lexical Access in which words are stored as hierarchical arrangements of distinctive features (Stevens, K. N. (2002). "Toward a model for lexical access based on acoustic landmarks and distinctive features," J. Acoust. Soc. Am., 111(4):1872-1891). Over the past few decades, the Speech Communication Group at the Massachusetts Institute of Technology (MIT) developed a speech recognition system for English based on this approach. Italian will be the first language beyond English to be explored; the extension to another language provides the opportunity to test the hypothesis that words are represented in memory as a set of hierarchically-arranged distinctive features, and reveal which of the underlying mechanisms may have a language-independent nature. This paper also introduces a new Lexical Access corpus, the LaMIT database, created and labeled specifically for this work, that will be provided freely to the speech research community. Future developments will test the hypothesis that specific acoustic discontinuities - called landmarks - that serve as cues to features, are language independent, while other cues may be language-dependent, with powerful implications for understanding how the human brain recognizes speech.
Lexical and syntactic gemination in Italian consonants -- Does a geminate Italian consonant consist of a repeated or a strengthened consonant?
Jan 25, 2021
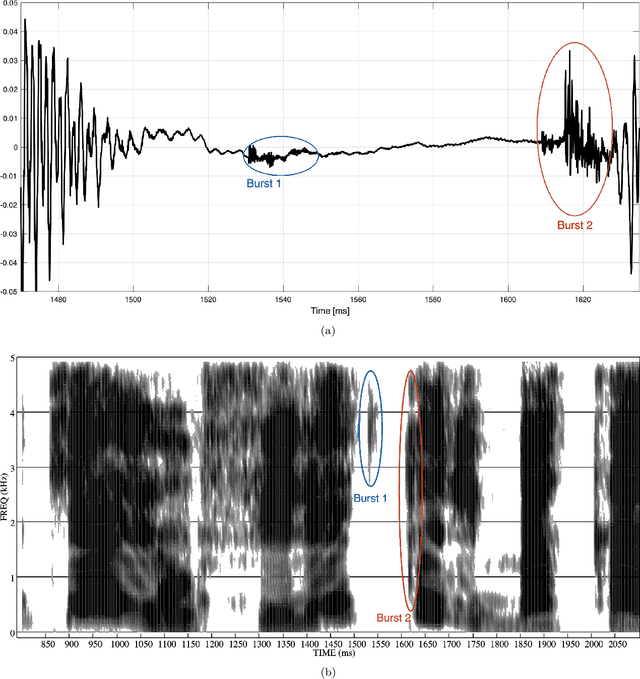

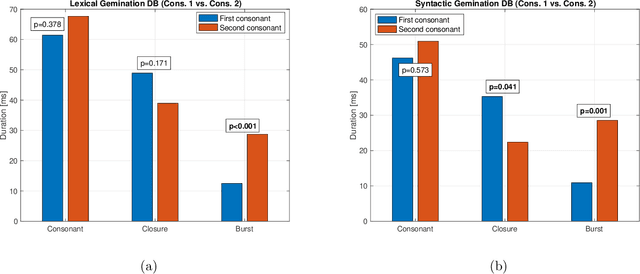
Two types of consonant gemination characterize Italian: lexical and syntactic. Italian lexical gemination is contrastive, so that two words may differ by only one geminated consonant. In contrast, syntactic gemination occurs across word boundaries, and affects the initial consonant of a word in specific contexts, such as the presence of a monosyllabic morpheme before the word. This study investigates the acoustic correlates of Italian lexical and syntactic gemination, asking if the correlates for the two types are similar in the case of stop consonants. Results confirmed previous studies showing that duration is a prominent gemination cue, with a lengthened consonant closure and a shortened pre-consonant vowel for both types. Results also revealed the presence, in about 10-12% of instances, of a double stop-release burst, providing strong support for the biphonematic nature of Italian geminated stop consonants. Moreover, the timing of these bursts suggests a different planning process for lexical vs. syntactic geminates. The second burst, when present, is accommodated within the closure interval in syntactic geminates, while lexical geminates are lengthened by the extra burst. This suggests that syntactic gemination occurs during a post-lexical phase of production planning, after timing has already been established.
Estimation of the Frequency of Occurrence of Italian Phonemes in Text
Jan 18, 2021

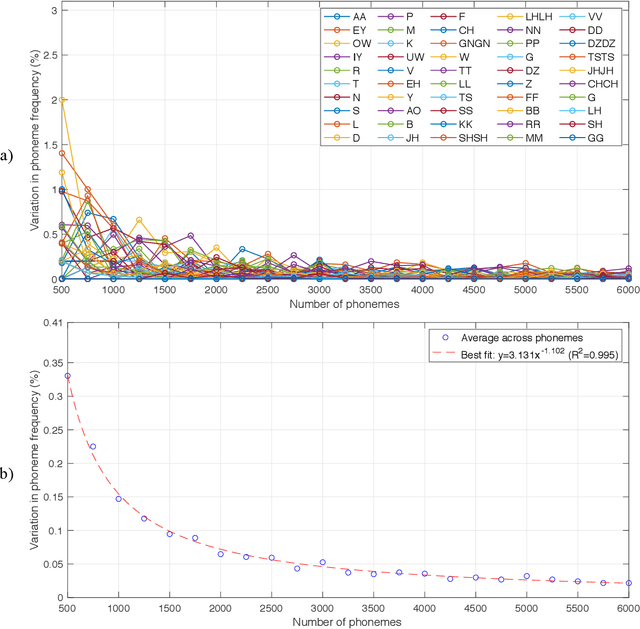
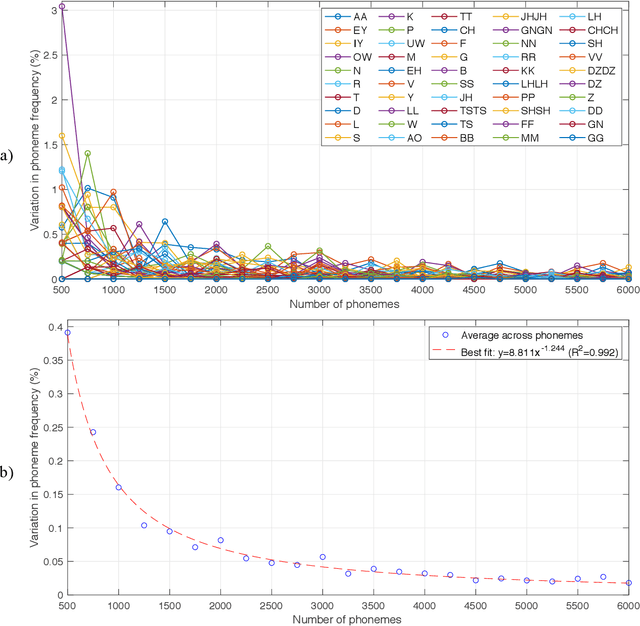
The purpose of this project was to derive a reliable estimate of the frequency of occurrence of the 30 phonemes - plus consonant geminated counterparts - of the Italian language, based on four selected written texts. Since no comparable dataset was found in previous literature, the present analysis may serve as a reference in future studies. Four textual sources were considered: Come si fa una tesi di laurea: le materie umanistiche by Umberto Eco, I promessi sposi by Alessandro Manzoni, a recent article in Corriere della Sera (a popular daily Italian newspaper), and In altre parole by Jhumpa Lahiri. The sources were chosen to represent varied genres, subject matter, time periods, and writing styles. Results of the analysis, which also included an analysis of variance, showed that, for all four sources, the frequencies of occurrence reached relatively stable values after about 6,000 phonemes (approx. 1,250 words), varying by <0.025%. Estimated frequencies are provided for each single source and as an average across sources.