 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyllableLM: Learning Coarse Semantic Units for Speech Language Models
Oct 05, 2024Language models require tokenized inputs. However, tokenization strategies for continuous data like audio and vision are often based on simple heuristics such as fixed sized convolutions or discrete clustering, which do not necessarily align with the semantic structure of the data. For speech in particular, the high resolution of waveforms (16,000 samples/second or more) presents a significant challenge as speech-based language models have had to use several times more tokens per word than text-based language models. In this work, we introduce a controllable self-supervised technique to merge speech representations into coarser syllable-like units while still preserving semantic information. We do this by 1) extracting noisy boundaries through analyzing correlations in pretrained encoder losses and 2) iteratively improving model representations with a novel distillation technique. Our method produces controllable-rate semantic units at as low as 5Hz and 60bps and achieves SotA in syllabic segmentation and clustering. Using these coarse tokens, we successfully train SyllableLM, a Speech Language Model (SpeechLM) that matches or outperforms current SotA SpeechLMs on a range of spoken language modeling tasks. SyllableLM also achieves significant improvements in efficiency with a 30x reduction in training compute and a 4x wall-clock inference speedup.
MAE-AST: Masked Autoencoding Audio Spectrogram Transformer
Mar 30, 2022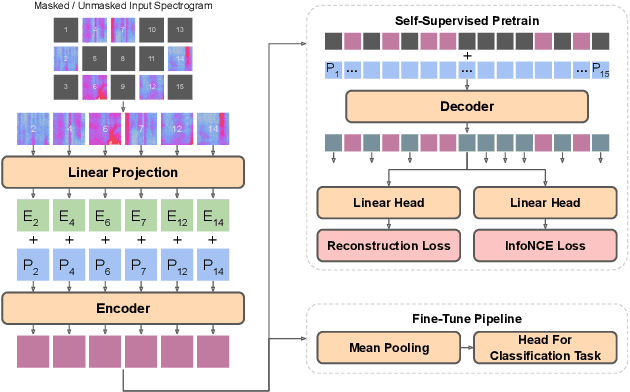
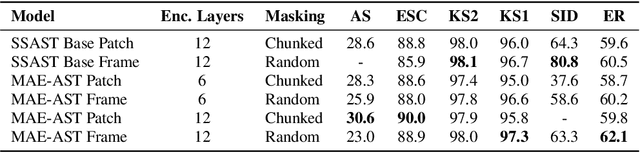

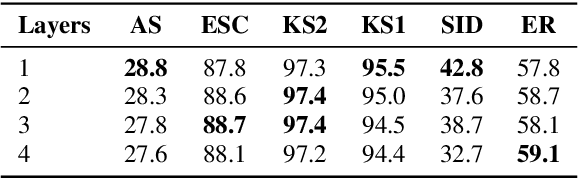
In this paper, we propose a simple yet powerful improvement over the recent Self-Supervised Audio Spectrogram Transformer (SSAST) model for speech and audio classification. Specifically, we leverage the insight that the SSAST uses a very high masking ratio (75%) during pretraining, meaning that the vast majority of self-attention compute is performed on mask tokens. We address this by integrating the encoder-decoder architecture from Masked Autoencoders are Scalable Vision Learners (MAE) into the SSAST, where a deep encoder operates on only unmasked input, and a shallow decoder operates on encoder outputs and mask tokens. We find that MAE-like pretraining can provide a 3x speedup and 2x memory usage reduction over the vanilla SSAST using current audio pretraining strategies with ordinary model and input sizes. When fine-tuning on downstream tasks, which only uses the encoder, we find that our approach outperforms the SSAST on a variety of downstream tasks. We further conduct comprehensive evaluations into different strategies of pretraining and explore differences in MAE-style pretraining between the visual and audio domains.