 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAE-AST: Masked Autoencoding Audio Spectrogram Transformer
Paper and Code
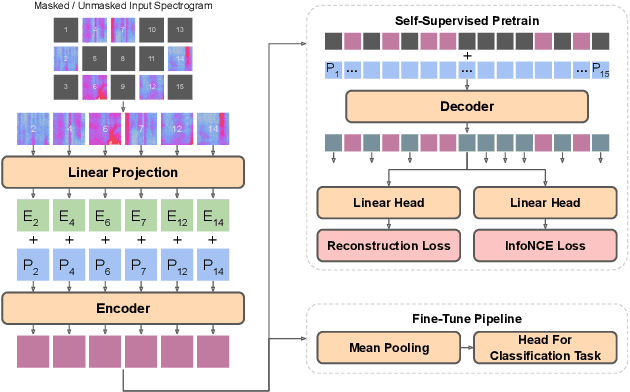
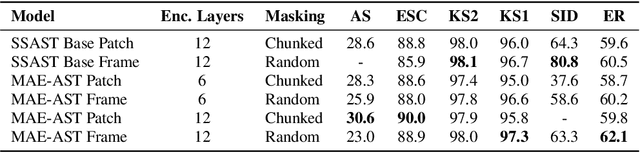

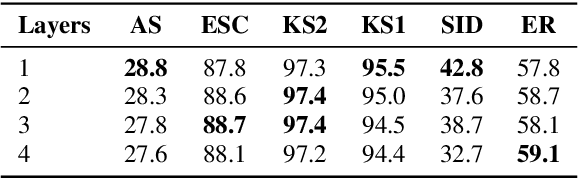
In this paper, we propose a simple yet powerful improvement over the recent Self-Supervised Audio Spectrogram Transformer (SSAST) model for speech and audio classification. Specifically, we leverage the insight that the SSAST uses a very high masking ratio (75%) during pretraining, meaning that the vast majority of self-attention compute is performed on mask tokens. We address this by integrating the encoder-decoder architecture from Masked Autoencoders are Scalable Vision Learners (MAE) into the SSAST, where a deep encoder operates on only unmasked input, and a shallow decoder operates on encoder outputs and mask tokens. We find that MAE-like pretraining can provide a 3x speedup and 2x memory usage reduction over the vanilla SSAST using current audio pretraining strategies with ordinary model and input sizes. When fine-tuning on downstream tasks, which only uses the encoder, we find that our approach outperforms the SSAST on a variety of downstream tasks. We further conduct comprehensive evaluations into different strategies of pretraining and explore differences in MAE-style pretraining between the visual and audio domains.