 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Memory Search: A Metaheuristic Approach for Optimizing Heuristic Search
Oct 22, 2024
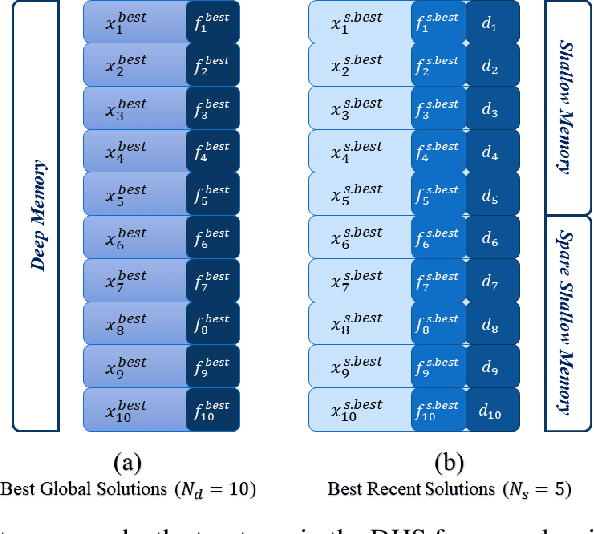


Metaheuristic search methods have proven to be essential tools for tackling complex optimization challenges, but their full potential is often constrained by conventional algorithmic frameworks. In this paper, we introduce a novel approach called Deep Heuristic Search (DHS), which models metaheuristic search as a memory-driven process. DHS employs multiple search layers and memory-based exploration-exploitation mechanisms to navigate large, dynamic search spaces. By utilizing model-free memory representations, DHS enhances the ability to traverse temporal trajectories without relying on probabilistic transition models. The proposed method demonstrates significant improvements in search efficiency and performance across a range of heuristic optimization problems.
Impact of emoji exclusion on the performance of Arabic sarcasm detection models
May 03, 2024



The complex challenge of detecting sarcasm in Arabic speech on social media is increased by the language diversity and the nature of sarcastic expressions. There is a significant gap in the capability of existing models to effectively interpret sarcasm in Arabic, which mandates the necessity for more sophisticated and precise detection methods. In this paper, we investigate the impact of a fundamental preprocessing component on sarcasm speech detection. While emojis play a crucial role in mitigating the absence effect of body language and facial expressions in modern communication, their impact on automated text analysis, particularly in sarcasm detection, remains underexplored. We investigate the impact of emoji exclusion from datasets on the performance of sarcasm detection models in social media content for Arabic as a vocabulary-super rich language. This investigation includes the adaptation and enhancement of AraBERT pre-training models, specifically by excluding emojis, to improve sarcasm detection capabilities. We use AraBERT pre-training to refine the specified models, demonstrating that the removal of emojis can significantly boost the accuracy of sarcasm detection. This approach facilitates a more refined interpretation of language, eliminating the potential confusion introduced by non-textual elements. The evaluated AraBERT models, through the focused strategy of emoji removal, adeptly navigate the complexities of Arabic sarcasm. This study establishes new benchmarks in Arabic natural language processing and presents valuable insights for social media platforms.
CGAN-ECT: Tomography Image Reconstruction from Electrical Capacitance Measurements Using CGANs
Sep 12, 2022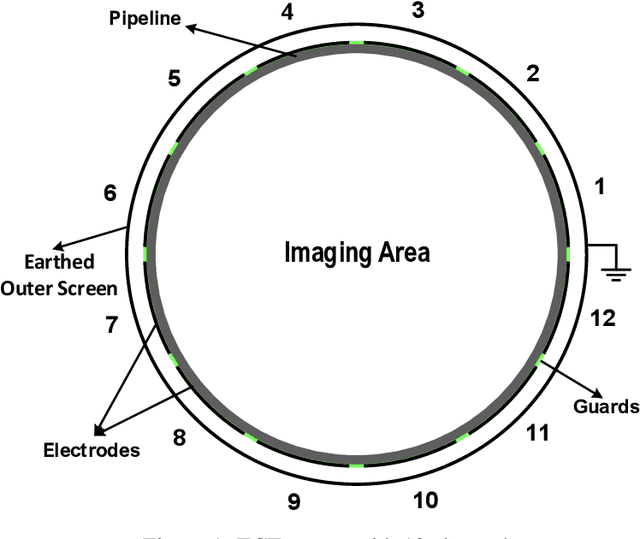
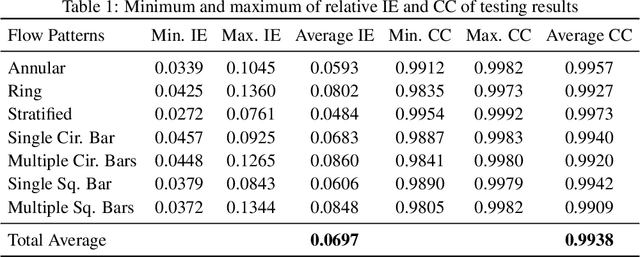
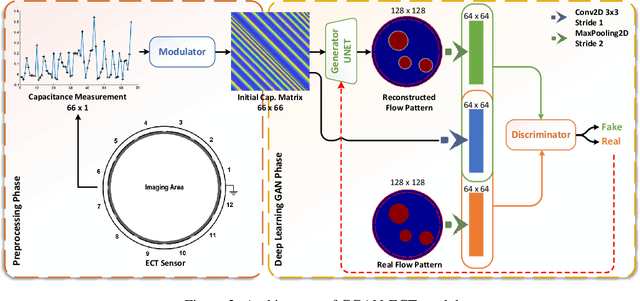
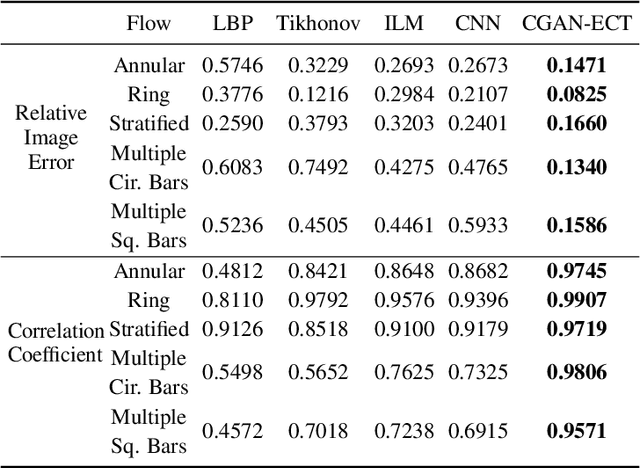
Due to the rapid growth of Electrical Capacitance Tomography (ECT) applications in several industrial fields, there is a crucial need for developing high quality, yet fast, methodologies of image reconstruction from raw capacitance measurements. Deep learning, as an effective non-linear mapping tool for complicated functions, has been going viral in many fields including electrical tomography. In this paper, we propose a Conditional Generative Adversarial Network (CGAN) model for reconstructing ECT images from capacitance measurements. The initial image of the CGAN model is constructed from the capacitance measurement. To our knowledge, this is the first time to represent the capacitance measurements in an image form. We have created a new massive ECT dataset of 320K synthetic image measurements pairs for training, and testing the proposed model. The feasibility and generalization ability of the proposed CGAN-ECT model are evaluated using testing dataset, contaminated data and flow patterns that are not exposed to the model during the training phase. The evaluation results prove that the proposed CGAN-ECT model can efficiently create more accurate ECT images than traditional and other deep learning-based image reconstruction algorithms. CGAN-ECT achieved an average image correlation coefficient of more than 99.3% and an average relative image error about 0.07.
Handling Missing Annotations in Supervised Learning Data
Feb 17, 2020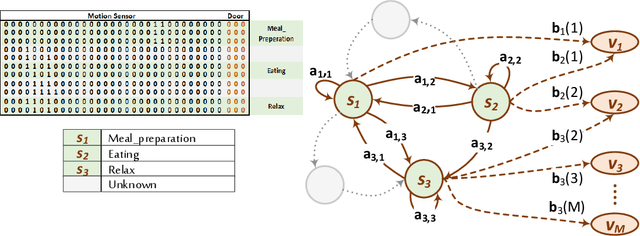
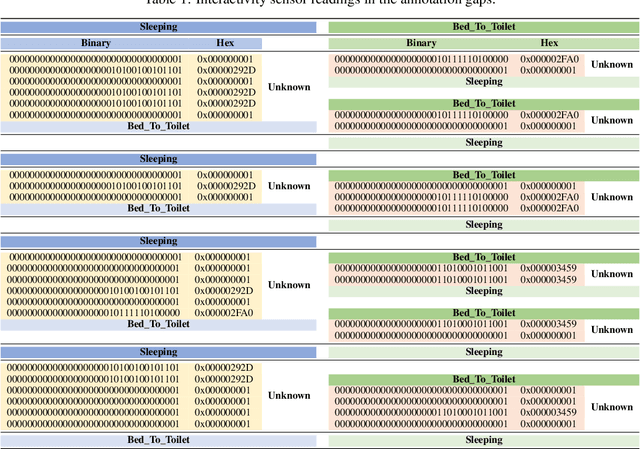
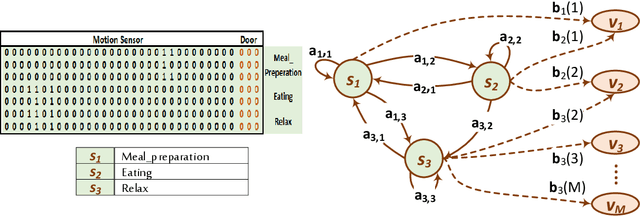
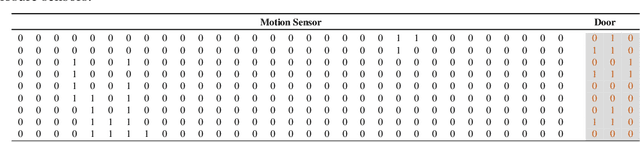
Data annotation is an essential stage in supervised learning. However, the annotation process is exhaustive and time consuming, specially for large datasets. Activities of Daily Living (ADL) recognition is an example of systems that exploit very large raw sensor data readings. In such systems, sensor readings are collected from activity-monitoring sensors in a 24/7 manner. The size of the generated dataset is so huge that it is almost impossible for a human annotator to give a certain label to every single instance in the dataset. This results in annotation gaps in the input data to the adopting supervised learning system. The performance of the recognition system is negatively affected by these gaps. In this work, we propose and investigate three different paradigms to handle these gaps. In the first paradigm, the gaps are taken out by dropping all unlabeled readings. A single "Unknown" or "Do-Nothing" label is given to the unlabeled readings within the operation of the second paradigm. The last paradigm handles these gaps by giving every one of them a unique label identifying the encapsulating deterministic labels. Also, we propose a semantic preprocessing method of annotation gaps by constructing a hybrid combination of some of these paradigms for further performance improvement. The performance of the proposed three paradigms and their hybrid combination is evaluated using an ADL benchmark dataset containing more than $2.5\times 10^6$ sensor readings that had been collected over more than nine months. The evaluation results emphasize the performance contrast under the operation of each paradigm and support a specific gap handling approach for better performance.
* 14 pages, 13 figures, 2 tables