 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling Missing Annotations in Supervised Learning Data
Paper and Code
Feb 17, 2020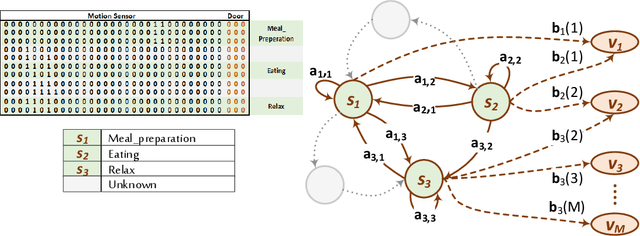
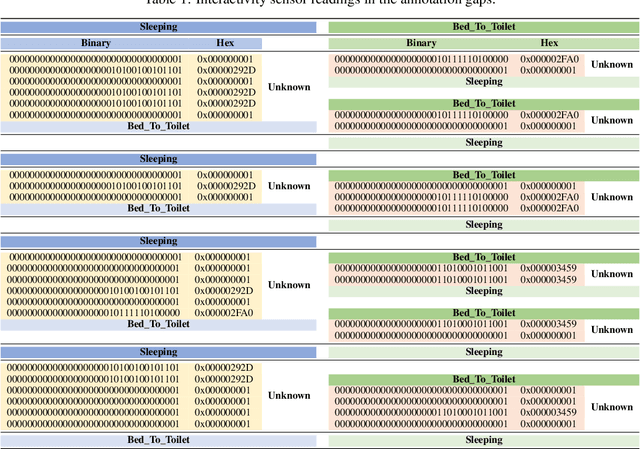
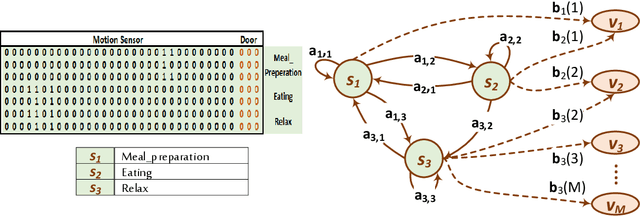
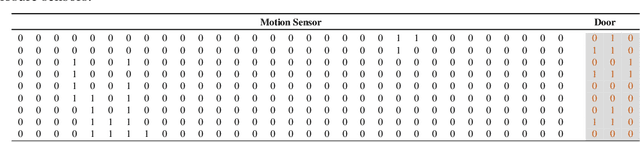
Data annotation is an essential stage in supervised learning. However, the annotation process is exhaustive and time consuming, specially for large datasets. Activities of Daily Living (ADL) recognition is an example of systems that exploit very large raw sensor data readings. In such systems, sensor readings are collected from activity-monitoring sensors in a 24/7 manner. The size of the generated dataset is so huge that it is almost impossible for a human annotator to give a certain label to every single instance in the dataset. This results in annotation gaps in the input data to the adopting supervised learning system. The performance of the recognition system is negatively affected by these gaps. In this work, we propose and investigate three different paradigms to handle these gaps. In the first paradigm, the gaps are taken out by dropping all unlabeled readings. A single "Unknown" or "Do-Nothing" label is given to the unlabeled readings within the operation of the second paradigm. The last paradigm handles these gaps by giving every one of them a unique label identifying the encapsulating deterministic labels. Also, we propose a semantic preprocessing method of annotation gaps by constructing a hybrid combination of some of these paradigms for further performance improvement. The performance of the proposed three paradigms and their hybrid combination is evaluated using an ADL benchmark dataset containing more than $2.5\times 10^6$ sensor readings that had been collected over more than nine months. The evaluation results emphasize the performance contrast under the operation of each paradigm and support a specific gap handling approach for better performance.