 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Explicable Policy Search
Mar 10, 2025When users work with AI agents, they form conscious or subconscious expectations of them. Meeting user expectations is crucial for such agents to engage in successful interactions and teaming. However, users may form expectations of an agent that differ from the agent's planned behaviors. These differences lead to the consideration of two separate decision models in the planning process to generate explicable behaviors. However, little has been done to incorporate safety considerations, especially in a learning setting. We present Safe Explicable Policy Search (SEPS), which aims to provide a learning approach to explicable behavior generation while minimizing the safety risk, both during and after learning. We formulate SEPS as a constrained optimization problem where the agent aims to maximize an explicability score subject to constraints on safety and a suboptimality criterion based on the agent's model. SEPS innovatively combines the capabilities of Constrained Policy Optimization and Explicable Policy Search. We evaluate SEPS in safety-gym environments and with a physical robot experiment to show that it can learn explicable behaviors that adhere to the agent's safety requirements and are efficient. Results show that SEPS can generate safe and explicable behaviors while ensuring a desired level of performance w.r.t. the agent's objective, and has real-world relevance in human-AI teaming.
Safe Explicable Robot Planning
Apr 04, 2023Human expectations stem from their knowledge of the others and the world. Where human-robot interaction is concerned, such knowledge about the robot may be inconsistent with the ground truth, resulting in the robot not meeting its expectations. Explicable planning was previously introduced as a novel planning approach to reconciling human expectations and the optimal robot behavior for more interpretable robot decision-making. One critical issue that remains unaddressed is safety during explicable decision-making which can lead to explicable behaviors that are unsafe. We propose Safe Explicable Planning (SEP), which extends explicable planning to support the specification of a safety bound. The objective of SEP is to find a policy that generates a behavior close to human expectations while satisfying the safety constraints introduced by the bound, which is a special case of multi-objective optimization where the solution to SEP lies on the Pareto frontier. Under such a formulation, we propose a novel and efficient method that returns the safe explicable policy and an approximate solution. In addition, we provide theoretical proof for the optimality of the exact solution under the designer-specified bound. Our evaluation results confirm the applicability and efficacy of our method for safe explicable planning.
Generating Active Explicable Plans in Human-Robot Teaming
Sep 18, 2021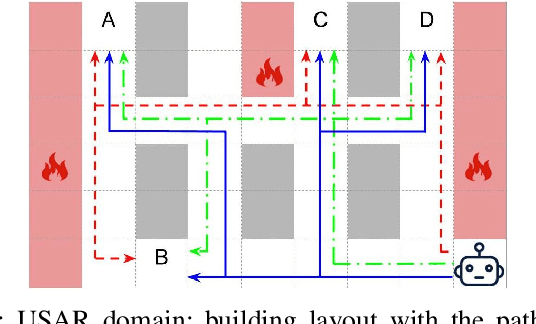

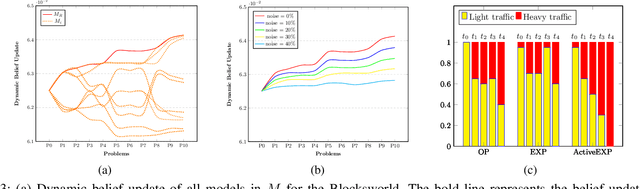

Intelligent robots are redefining a multitude of critical domains but are still far from being fully capable of assisting human peers in day-to-day tasks. An important requirement of collaboration is for each teammate to maintain and respect an understanding of the others' expectations of itself. Lack of which may lead to serious issues such as loose coordination between teammates, reduced situation awareness, and ultimately teaming failures. Hence, it is important for robots to behave explicably by meeting the human's expectations. One of the challenges here is that the expectations of the human are often hidden and can change dynamically as the human interacts with the robot. However, existing approaches to generating explicable plans often assume that the human's expectations are known and static. In this paper, we propose the idea of active explicable planning to relax this assumption. We apply a Bayesian approach to model and predict dynamic human belief and expectations to make explicable planning more anticipatory. We hypothesize that active explicable plans can be more efficient and explicable at the same time, when compared to explicable plans generated by the existing methods. In our experimental evaluation, we verify that our approach generates more efficient explicable plans while successfully capturing the dynamic belief change of the human teammate.