 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Guided Early Screening of Cervical Cancer
Nov 19, 2024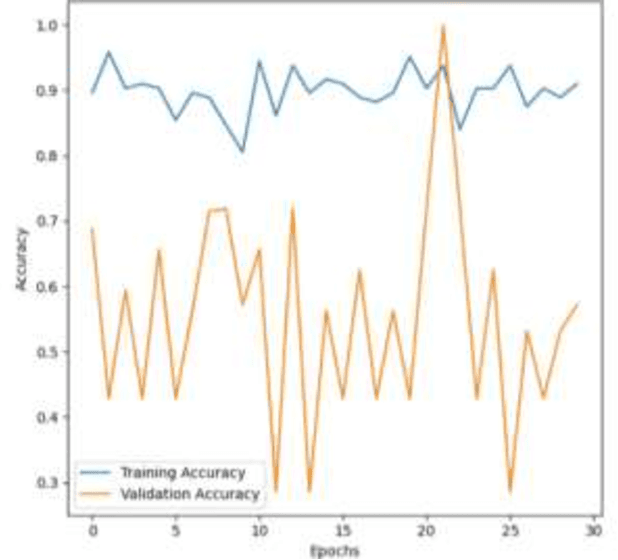
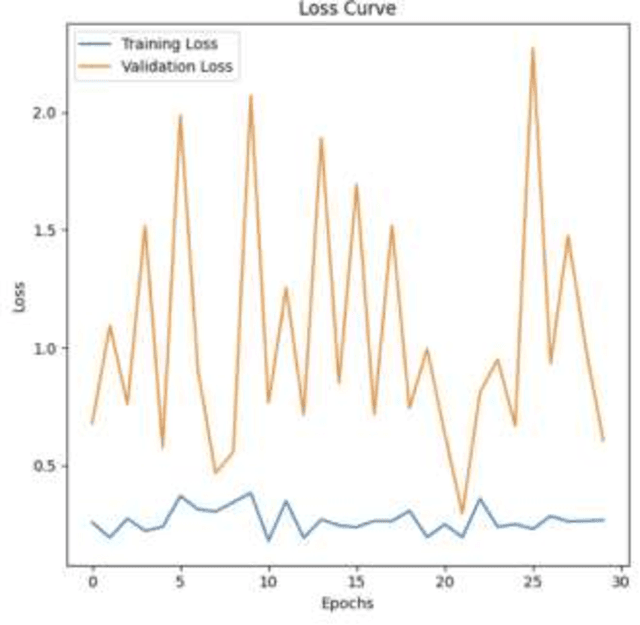
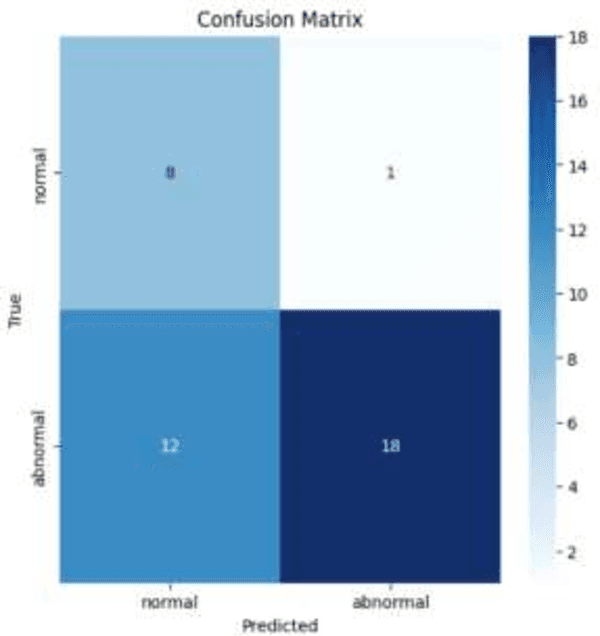

In order to support the creation of reliable machine learning models for anomaly detection, this project focuses on preprocessing, enhancing, and organizing a medical imaging dataset. There are two classifications in the dataset: normal and abnormal, along with extra noise fluctuations. In order to improve the photographs' quality, undesirable artifacts, including visible medical equipment at the edges, were eliminated using central cropping. Adjusting the brightness and contrast was one of the additional preprocessing processes. Normalization was then performed to normalize the data. To make classification jobs easier, the dataset was methodically handled by combining several image subsets into two primary categories: normal and pathological. To provide a strong training set that adapts well to real-world situations, sophisticated picture preprocessing techniques were used, such as contrast enhancement and real-time augmentation (including rotations, zooms, and brightness modifications). To guarantee efficient model evaluation, the data was subsequently divided into training and testing subsets. In order to create precise and effective machine learning models for medical anomaly detection, high-quality input data is ensured via this thorough approach. Because of the project pipeline's flexible and scalable design, it can be easily integrated with bigger clinical decision-support systems.