 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeView-labels Are Indispensable: A Multifacet Complementarity Study of Multi-view Clustering
May 05, 2022

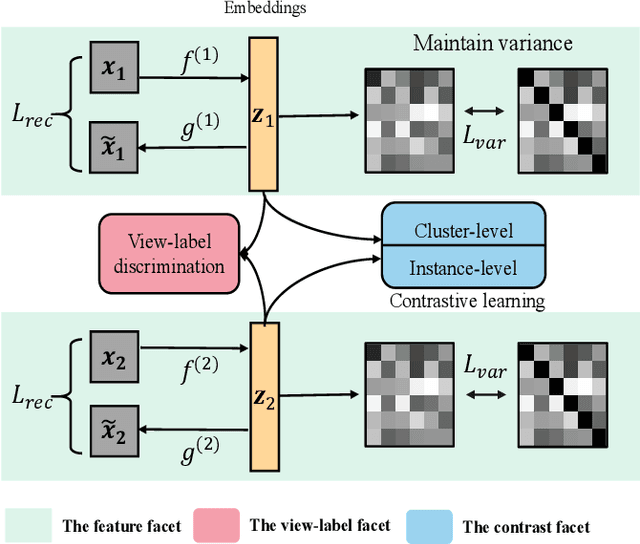

Consistency and complementarity are two key ingredients for boosting multi-view clustering (MVC). Recently with the introduction of popular contrastive learning, the consistency learning of views has been further enhanced in MVC, leading to promising performance. However, by contrast, the complementarity has not received sufficient attention except just in the feature facet, where the Hilbert Schmidt Independence Criterion (HSIC) term or the independent encoder-decoder network is usually adopted to capture view-specific information. This motivates us to reconsider the complementarity learning of views comprehensively from multiple facets including the feature-, view-label- and contrast- facets, while maintaining the view consistency. We empirically find that all the facets contribute to the complementarity learning, especially the view-label facet, which is usually neglected by existing methods. Based on this, we develop a novel \underline{M}ultifacet \underline{C}omplementarity learning framework for \underline{M}ulti-\underline{V}iew \underline{C}lustering (MCMVC), which fuses multifacet complementarity information, especially explicitly embedding the view-label information. To our best knowledge, it is the first time to use view-labels explicitly to guide the complementarity learning of views. Compared with the SOTA baseline, MCMVC achieves remarkable improvements, e.g., by average margins over $5.00\%$ and $7.00\%$ respectively in complete and incomplete MVC settings on Caltech101-20 in terms of three evaluation metrics.
Universum-inspired Supervised Contrastive Learning
Apr 22, 2022
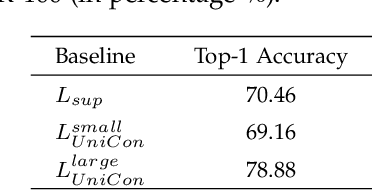


Mixup is an efficient data augmentation method which generates additional samples through respective convex combinations of original data points and labels. Although being theoretically dependent on data properties, Mixup is reported to perform well as a regularizer and calibrator contributing reliable robustness and generalization to neural network training. In this paper, inspired by Universum Learning which uses out-of-class samples to assist the target tasks, we investigate Mixup from a largely under-explored perspective - the potential to generate in-domain samples that belong to none of the target classes, that is, universum. We find that in the framework of supervised contrastive learning, universum-style Mixup produces surprisingly high-quality hard negatives, greatly relieving the need for a large batch size in contrastive learning. With these findings, we propose Universum-inspired Contrastive learning (UniCon), which incorporates Mixup strategy to generate universum data as g-negatives and pushes them apart from anchor samples of the target classes. Our approach not only improves Mixup with hard labels, but also innovates a novel measure to generate universum data. With a linear classifier on the learned representations, our method achieves 81.68% top-1 accuracy on CIFAR-100, surpassing the state of art by a significant margin of 5% with a much smaller batch size, typically, 256 in UniCon vs. 1024 in SupCon using ResNet-50.