 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Does Overparameterization Affect Features?
Jul 01, 2024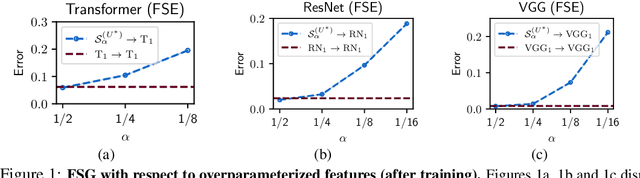
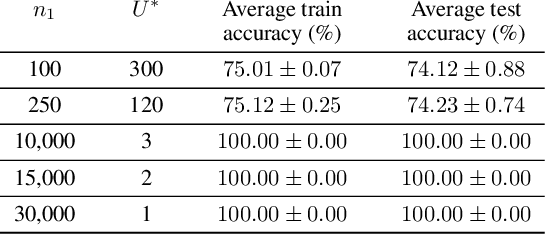
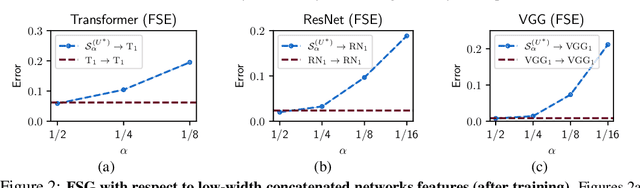

Overparameterization, the condition where models have more parameters than necessary to fit their training loss, is a crucial factor for the success of deep learning. However, the characteristics of the features learned by overparameterized networks are not well understood. In this work, we explore this question by comparing models with the same architecture but different widths. We first examine the expressivity of the features of these models, and show that the feature space of overparameterized networks cannot be spanned by concatenating many underparameterized features, and vice versa. This reveals that both overparameterized and underparameterized networks acquire some distinctive features. We then evaluate the performance of these models, and find that overparameterized networks outperform underparameterized networks, even when many of the latter are concatenated. We corroborate these findings using a VGG-16 and ResNet18 on CIFAR-10 and a Transformer on the MNLI classification dataset. Finally, we propose a toy setting to explain how overparameterized networks can learn some important features that the underparamaterized networks cannot learn.