 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Depth Estimation using Location Information
Dec 27, 2021
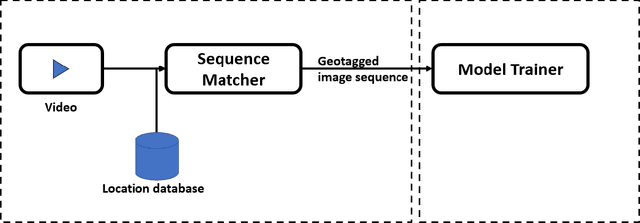
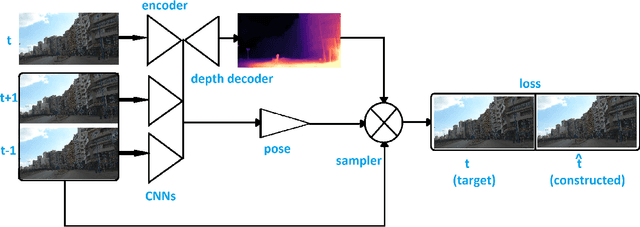
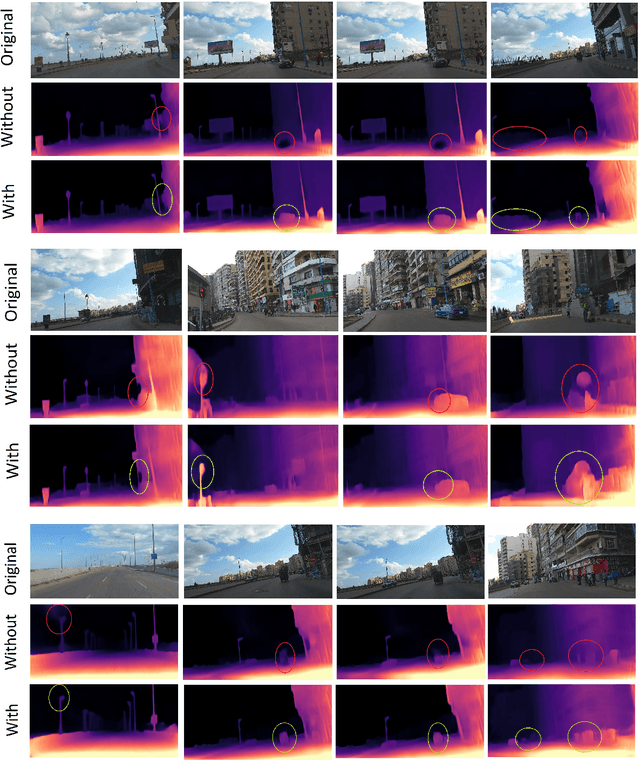
The ability to accurately estimate depth information is crucial for many autonomous applications to recognize the surrounded environment and predict the depth of important objects. One of the most recently used techniques is monocular depth estimation where the depth map is inferred from a single image. This paper improves the self-supervised deep learning techniques to perform accurate generalized monocular depth estimation. The main idea is to train the deep model to take into account a sequence of the different frames, each frame is geotagged with its location information. This makes the model able to enhance depth estimation given area semantics. We demonstrate the effectiveness of our model to improve depth estimation results. The model is trained in a realistic environment and the results show improvements in the depth map after adding the location data to the model training phase.