 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtecting Intellectual Property of EEG-based Neural Networks with Watermarking
Feb 09, 2025EEG-based neural networks, pivotal in medical diagnosis and brain-computer interfaces, face significant intellectual property (IP) risks due to their reliance on sensitive neurophysiological data and resource-intensive development. Current watermarking methods, particularly those using abstract trigger sets, lack robust authentication and fail to address the unique challenges of EEG models. This paper introduces a cryptographic wonder filter-based watermarking framework tailored for EEG-based neural networks. Leveraging collision-resistant hashing and public-key encryption, the wonder filter embeds the watermark during training, ensuring minimal distortion ($\leq 5\%$ drop in EEG task accuracy) and high reliability (100\% watermark detection). The framework is rigorously evaluated against adversarial attacks, including fine-tuning, transfer learning, and neuron pruning. Results demonstrate persistent watermark retention, with classification accuracy for watermarked states remaining above 90\% even after aggressive pruning, while primary task performance degrades faster, deterring removal attempts. Piracy resistance is validated by the inability to embed secondary watermarks without severe accuracy loss ( $>10\%$ in EEGNet and CCNN models). Cryptographic hashing ensures authentication, reducing brute-force attack success probabilities. Evaluated on the DEAP dataset across models (CCNN, EEGNet, TSception), the method achieves $>99.4\%$ null-embedding accuracy, effectively eliminating false positives. By integrating wonder filters with EEG-specific adaptations, this work bridges a critical gap in IP protection for neurophysiological models, offering a secure, tamper-proof solution for healthcare and biometric applications. The framework's robustness against adversarial modifications underscores its potential to safeguard sensitive EEG models while maintaining diagnostic utility.
Invizo: Arabic Handwritten Document Optical Character Recognition Solution
Feb 07, 2025Converting images of Arabic text into plain text is a widely researched topic in academia and industry. However, recognition of Arabic handwritten and printed text presents difficult challenges due to the complex nature of variations of the Arabic script. This work proposes an end-to-end solution for recognizing Arabic handwritten, printed, and Arabic numbers and presents the data in a structured manner. We reached 81.66% precision, 78.82% Recall, and 79.07% F-measure on a Text Detection task that powers the proposed solution. The proposed recognition model incorporates state-of-the-art CNN-based feature extraction, and Transformer-based sequence modeling to accommodate variations in handwriting styles, stroke thicknesses, alignments, and noise conditions. The evaluation of the model suggests its strong performances on both printed and handwritten texts, yielding 0.59% CER and & 1.72% WER on printed text, and 7.91% CER and 31.41% WER on handwritten text. The overall proposed solution has proven to be relied on in real-life OCR tasks. Equipped with both detection and recognition models as well as other Feature Extraction and Matching helping algorithms. With the general purpose implementation, making the solution valid for any given document or receipt that is Arabic handwritten or printed. Thus, it is practical and useful for any given context.
EfficientVITON: An Efficient Virtual Try-On Model using Optimized Diffusion Process
Jan 20, 2025Would not it be much more convenient for everybody to try on clothes by only looking into a mirror ? The answer to that problem is virtual try-on, enabling users to digitally experiment with outfits. The core challenge lies in realistic image-to-image translation, where clothing must fit diverse human forms, poses, and figures. Early methods, which used 2D transformations, offered speed, but image quality was often disappointing and lacked the nuance of deep learning. Though GAN-based techniques enhanced realism, their dependence on paired data proved limiting. More adaptable methods offered great visuals but demanded significant computing power and time. Recent advances in diffusion models have shown promise for high-fidelity translation, yet the current crop of virtual try-on tools still struggle with detail loss and warping issues. To tackle these challenges, this paper proposes EfficientVITON, a new virtual try-on system leveraging the impressive pre-trained Stable Diffusion model for better images and deployment feasibility. The system includes a spatial encoder to maintain clothings finer details and zero cross-attention blocks to capture the subtleties of how clothes fit a human body. Input images are carefully prepared, and the diffusion process has been tweaked to significantly cut generation time without image quality loss. The training process involves two distinct stages of fine-tuning, carefully incorporating a balance of loss functions to ensure both accurate try-on results and high-quality visuals. Rigorous testing on the VITON-HD dataset, supplemented with real-world examples, has demonstrated that EfficientVITON achieves state-of-the-art results.
Arabic Handwritten Document OCR Solution with Binarization and Adaptive Scale Fusion Detection
Dec 02, 2024



The problem of converting images of text into plain text is a widely researched topic in both academia and industry. Arabic handwritten Text Recognation (AHTR) poses additional challenges due to diverse handwriting styles and limited labeled data. In this paper we present a complete OCR pipeline that starts with line segmentation using Differentiable Binarization and Adaptive Scale Fusion techniques to ensure accurate detection of text lines. Following segmentation, a CNN-BiLSTM-CTC architecture is applied to recognize characters. Our system, trained on the Arabic Multi-Fonts Dataset (AMFDS), achieves a Character Recognition Rate (CRR) of 99.20% and a Word Recognition Rate (WRR) of 93.75% on single-word samples containing 7 to 10 characters, along with a CRR of 83.76% for sentences. These results demonstrate the system's strong performance in handling Arabic scripts, establishing a new benchmark for AHTR systems.
MARL-FWC: Optimal Coordination of Freeway Traffic Control Measures
Aug 27, 2018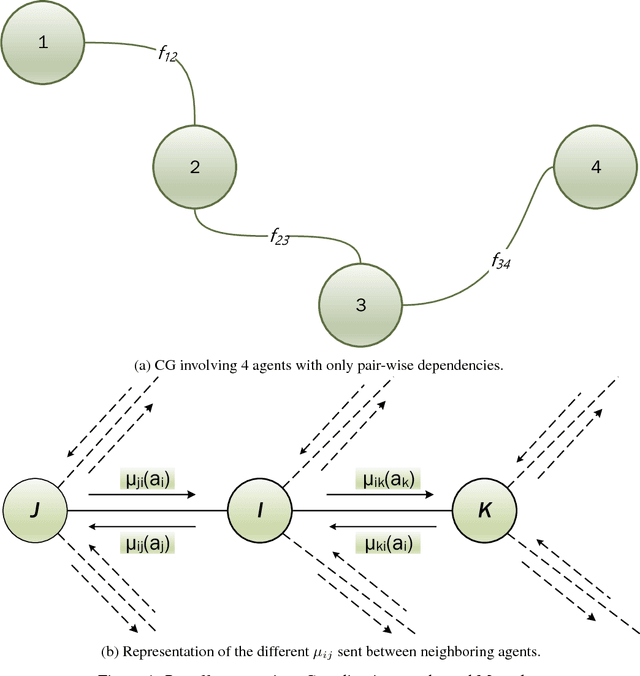

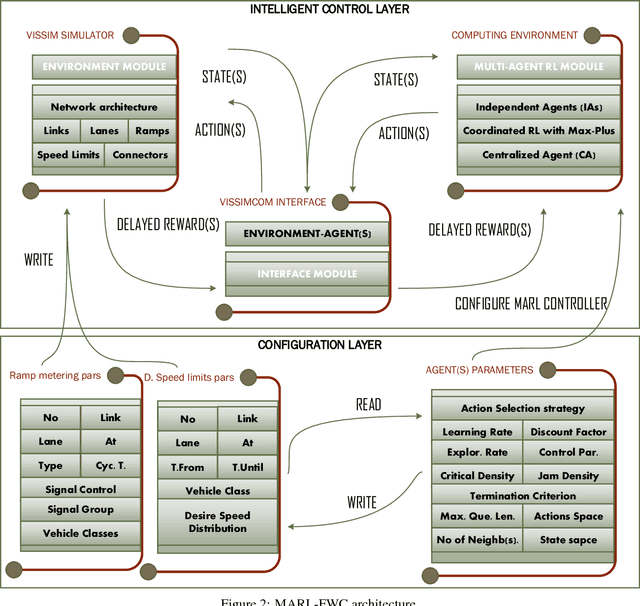
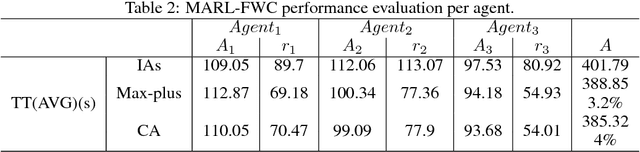
The objective of this article is to optimize the overall traffic flow on freeways using multiple ramp metering controls plus its complementary Dynamic Speed Limits (DSLs). An optimal freeway operation can be reached when minimizing the difference between the freeway density and the critical ratio for maximum traffic flow. In this article, a Multi-Agent Reinforcement Learning for Freeways Control (MARL-FWC) system for ramps metering and DSLs is proposed. MARL-FWC introduces a new microscopic framework at the network level based on collaborative Markov Decision Process modeling (Markov game) and an associated cooperative Q-learning algorithm. The technique incorporates payoff propagation (Max-Plus algorithm) under the coordination graphs framework, particularly suited for optimal control purposes. MARL-FWC provides three control designs: fully independent, fully distributed, and centralized; suited for different network architectures. MARL-FWC was extensively tested in order to assess the proposed model of the joint payoff, as well as the global payoff. Experiments are conducted with heavy traffic flow under the renowned VISSIM traffic simulator to evaluate MARL-FWC. The experimental results show a significant decrease in the total travel time and an increase in the average speed (when compared with the base case) while maintaining an optimal traffic flow.