 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the inference gap in Mutimodal Variational Autoencoders
Feb 06, 2025From medical diagnosis to autonomous vehicles, critical applications rely on the integration of multiple heterogeneous data modalities. Multimodal Variational Autoencoders offer versatile and scalable methods for generating unobserved modalities from observed ones. Recent models using mixturesof-experts aggregation suffer from theoretically grounded limitations that restrict their generation quality on complex datasets. In this article, we propose a novel interpretable model able to learn both joint and conditional distributions without introducing mixture aggregation. Our model follows a multistage training process: first modeling the joint distribution with variational inference and then modeling the conditional distributions with Normalizing Flows to better approximate true posteriors. Importantly, we also propose to extract and leverage the information shared between modalities to improve the conditional coherence of generated samples. Our method achieves state-of-the-art results on several benchmark datasets.
Improving Multimodal Joint Variational Autoencoders through Normalizing Flows and Correlation Analysis
May 19, 2023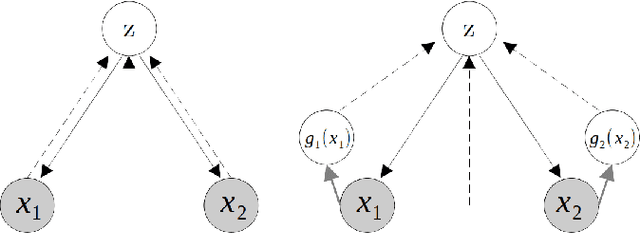
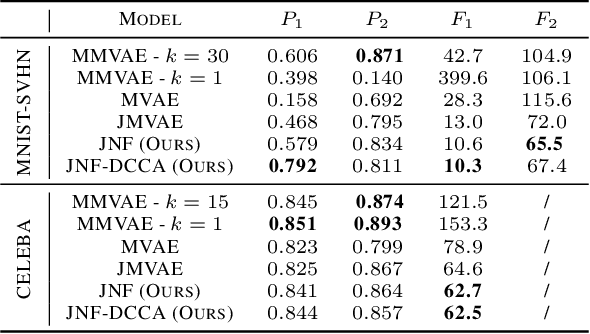
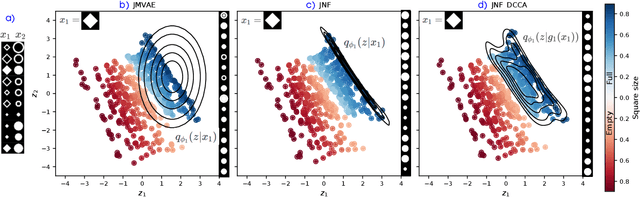
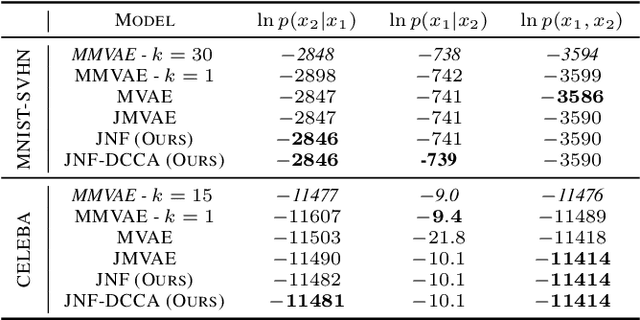
We propose a new multimodal variational autoencoder that enables to generate from the joint distribution and conditionally to any number of complex modalities. The unimodal posteriors are conditioned on the Deep Canonical Correlation Analysis embeddings which preserve the shared information across modalities leading to more coherent cross-modal generations. Furthermore, we use Normalizing Flows to enrich the unimodal posteriors and achieve more diverse data generation. Finally, we propose to use a Product of Experts for inferring one modality from several others which makes the model scalable to any number of modalities. We demonstrate that our method improves likelihood estimates, diversity of the generations and in particular coherence metrics in the conditional generations on several datasets.