 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGASP: Efficient Black-Box Generation of Adversarial Suffixes for Jailbreaking LLMs
Nov 21, 2024

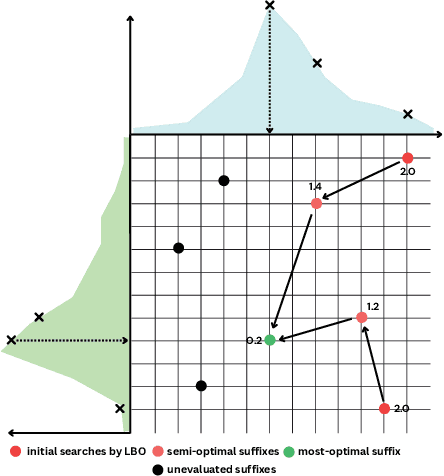

Large Language Models (LLMs) have shown impressive proficiency across a range of natural language processing tasks yet remain vulnerable to adversarial prompts, known as jailbreak attacks, carefully designed to elicit harmful responses from LLMs. Traditional methods rely on manual heuristics, which suffer from limited generalizability. While being automatic, optimization-based attacks often produce unnatural jailbreak prompts that are easy to detect by safety filters or require high computational overhead due to discrete token optimization. Witnessing the limitations of existing jailbreak methods, we introduce Generative Adversarial Suffix Prompter (GASP), a novel framework that combines human-readable prompt generation with Latent Bayesian Optimization (LBO) to improve adversarial suffix creation in a fully black-box setting. GASP leverages LBO to craft adversarial suffixes by efficiently exploring continuous embedding spaces, gradually optimizing the model to improve attack efficacy while balancing prompt coherence through a targeted iterative refinement procedure. Our experiments show that GASP can generate natural jailbreak prompts, significantly improving attack success rates, reducing training times, and accelerating inference speed, thus making it an efficient and scalable solution for red-teaming LLMs.
When Less is More: Achieving Faster Convergence in Distributed Edge Machine Learning
Oct 27, 2024Distributed Machine Learning (DML) on resource-constrained edge devices holds immense potential for real-world applications. However, achieving fast convergence in DML in these heterogeneous environments remains a significant challenge. Traditional frameworks like Bulk Synchronous Parallel and Asynchronous Stochastic Parallel rely on frequent, small updates that incur substantial communication overhead and hinder convergence speed. Furthermore, these frameworks often employ static dataset sizes, neglecting the heterogeneity of edge devices and potentially leading to straggler nodes that slow down the entire training process. The straggler nodes, i.e., edge devices that take significantly longer to process their assigned data chunk, hinder the overall training speed. To address these limitations, this paper proposes Hermes, a novel probabilistic framework for efficient DML on edge devices. This framework leverages a dynamic threshold based on recent test loss behavior to identify statistically significant improvements in the model's generalization capability, hence transmitting updates only when major improvements are detected, thereby significantly reducing communication overhead. Additionally, Hermes employs dynamic dataset allocation to optimize resource utilization and prevents performance degradation caused by straggler nodes. Our evaluations on a real-world heterogeneous resource-constrained environment demonstrate that Hermes achieves faster convergence compared to state-of-the-art methods, resulting in a remarkable $13.22$x reduction in training time and a $62.1\%$ decrease in communication overhead.