 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrowing Cosine Unit: A Novel Oscillatory Activation Function That Can Speedup Training and Reduce Parameters in Convolutional Neural Networks
Sep 04, 2021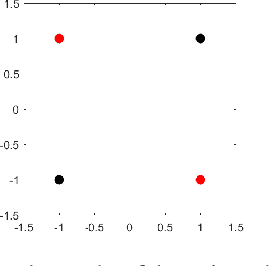
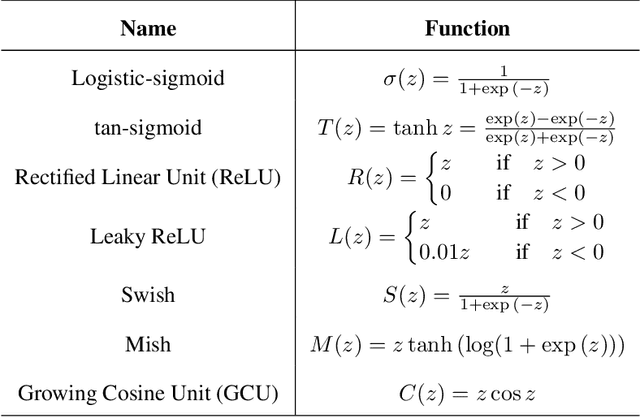
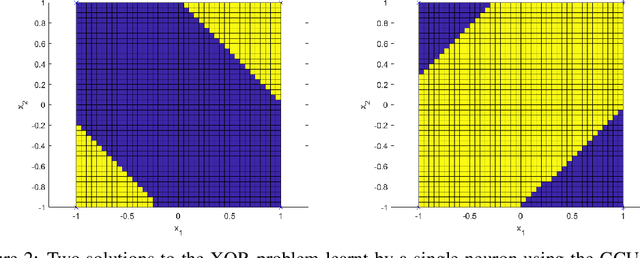
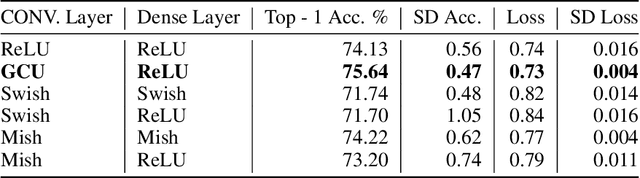
Convolution neural networks have been successful in solving many socially important and economically significant problems. Their ability to learn complex high-dimensional functions hierarchically can be attributed to the use of nonlinear activation functions. A key discovery that made training deep networks feasible was the adoption of the Rectified Linear Unit (ReLU) activation function to alleviate the vanishing gradient problem caused by using saturating activation functions. Since then many improved variants of the ReLU activation have been proposed. However a majority of activation functions used today are non-oscillatory and monotonically increasing due to their biological plausibility. This paper demonstrates that oscillatory activation functions can improve gradient flow and reduce network size. It is shown that oscillatory activation functions allow neurons to switch classification (sign of output) within the interior of neuronal hyperplane positive and negative half-spaces allowing complex decisions with fewer neurons. A new oscillatory activation function C(z) = z cos z that outperforms Sigmoids, Swish, Mish and ReLU on a variety of architectures and benchmarks is presented. This new activation function allows even single neurons to exhibit nonlinear decision boundaries. This paper presents a single neuron solution to the famous XOR problem. Experimental results indicate that replacing the activation function in the convolutional layers with C(z) significantly improves performance on CIFAR-10, CIFAR-100 and Imagenette.