 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning What NOT to Count
Apr 16, 2025Few/zero-shot object counting methods reduce the need for extensive annotations but often struggle to distinguish between fine-grained categories, especially when multiple similar objects appear in the same scene. To address this limitation, we propose an annotation-free approach that enables the seamless integration of new fine-grained categories into existing few/zero-shot counting models. By leveraging latent generative models, we synthesize high-quality, category-specific crowded scenes, providing a rich training source for adapting to new categories without manual labeling. Our approach introduces an attention prediction network that identifies fine-grained category boundaries trained using only synthetic pseudo-annotated data. At inference, these fine-grained attention estimates refine the output of existing few/zero-shot counting networks. To benchmark our method, we further introduce the FGTC dataset, a taxonomy-specific fine-grained object counting dataset for natural images. Our method substantially enhances pre-trained state-of-the-art models on fine-grained taxon counting tasks, while using only synthetic data. Code and data to be released upon acceptance.
AFreeCA: Annotation-Free Counting for All
Mar 07, 2024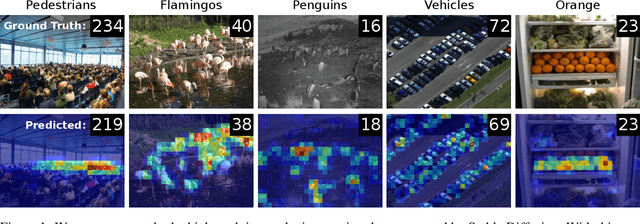

Object counting methods typically rely on manually annotated datasets. The cost of creating such datasets has restricted the versatility of these networks to count objects from specific classes (such as humans or penguins), and counting objects from diverse categories remains a challenge. The availability of robust text-to-image latent diffusion models (LDMs) raises the question of whether these models can be utilized to generate counting datasets. However, LDMs struggle to create images with an exact number of objects based solely on text prompts but they can be used to offer a dependable \textit{sorting} signal by adding and removing objects within an image. Leveraging this data, we initially introduce an unsupervised sorting methodology to learn object-related features that are subsequently refined and anchored for counting purposes using counting data generated by LDMs. Further, we present a density classifier-guided method for dividing an image into patches containing objects that can be reliably counted. Consequently, we can generate counting data for any type of object and count them in an unsupervised manner. Our approach outperforms other unsupervised and few-shot alternatives and is not restricted to specific object classes for which counting data is available. Code to be released upon acceptance.
SYRAC: Synthesize, Rank, and Count
Oct 11, 2023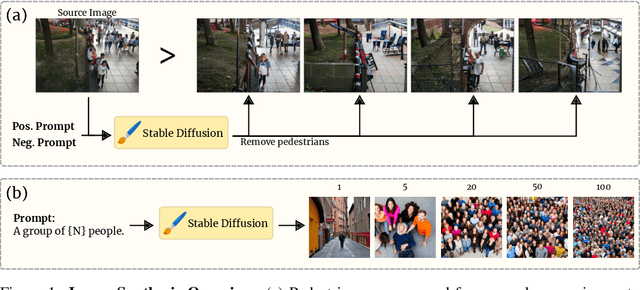
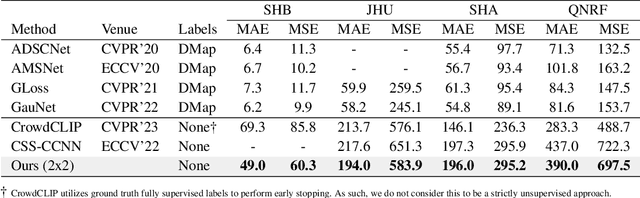


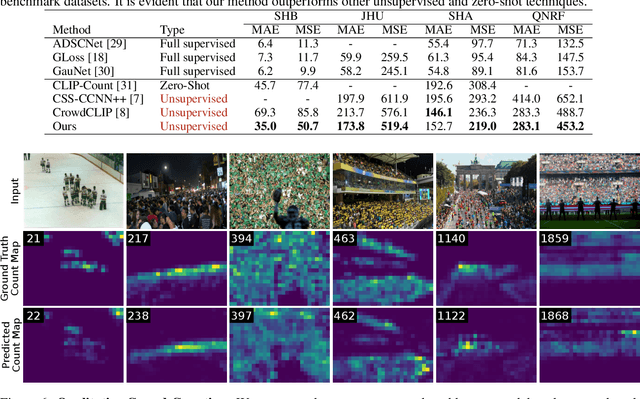
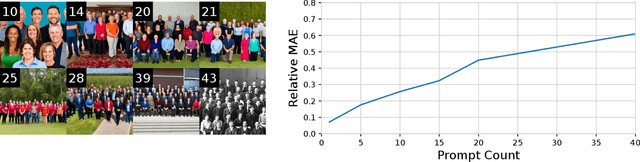
Crowd counting is a critical task in computer vision, with several important applications. However, existing counting methods rely on labor-intensive density map annotations, necessitating the manual localization of each individual pedestrian. While recent efforts have attempted to alleviate the annotation burden through weakly or semi-supervised learning, these approaches fall short of significantly reducing the workload. We propose a novel approach to eliminate the annotation burden by leveraging latent diffusion models to generate synthetic data. However, these models struggle to reliably understand object quantities, leading to noisy annotations when prompted to produce images with a specific quantity of objects. To address this, we use latent diffusion models to create two types of synthetic data: one by removing pedestrians from real images, which generates ranked image pairs with a weak but reliable object quantity signal, and the other by generating synthetic images with a predetermined number of objects, offering a strong but noisy counting signal. Our method utilizes the ranking image pairs for pre-training and then fits a linear layer to the noisy synthetic images using these crowd quantity features. We report state-of-the-art results for unsupervised crowd counting.