 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling A Network AI Gym for Autonomous Cyber Agents
Apr 03, 2023This work aims to enable autonomous agents for network cyber operations (CyOps) by applying reinforcement and deep reinforcement learning (RL/DRL). The required RL training environment is particularly challenging, as it must balance the need for high-fidelity, best achieved through real network emulation, with the need for running large numbers of training episodes, best achieved using simulation. A unified training environment, namely the Cyber Gym for Intelligent Learning (CyGIL) is developed where an emulated CyGIL-E automatically generates a simulated CyGIL-S. From preliminary experimental results, CyGIL-S is capable to train agents in minutes compared with the days required in CyGIL-E. The agents trained in CyGIL-S are transferrable directly to CyGIL-E showing full decision proficiency in the emulated "real" network. Enabling offline RL, the CyGIL solution presents a promising direction towards sim-to-real for leveraging RL agents in real-world cyber networks.
Unified Emulation-Simulation Training Environment for Autonomous Cyber Agents
Apr 03, 2023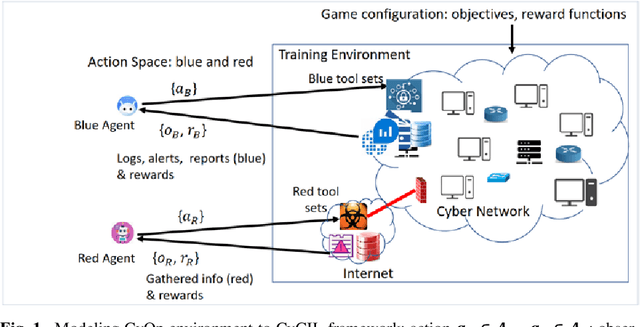
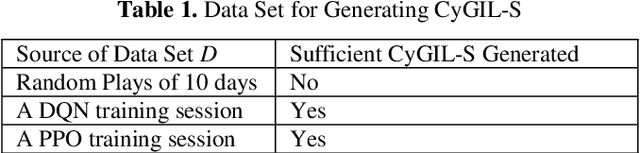
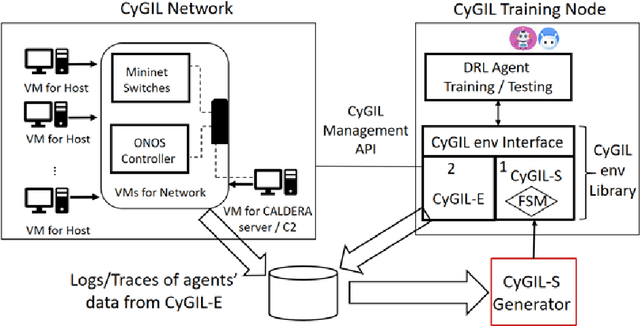
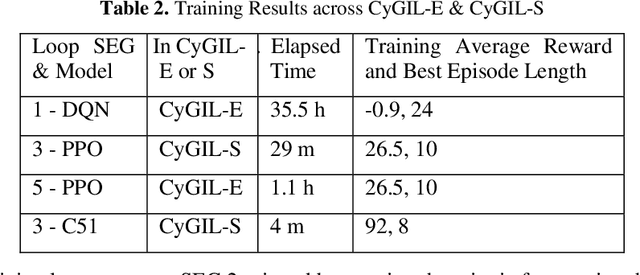
Autonomous cyber agents may be developed by applying reinforcement and deep reinforcement learning (RL/DRL), where agents are trained in a representative environment. The training environment must simulate with high-fidelity the network Cyber Operations (CyOp) that the agent aims to explore. Given the complexity of net-work CyOps, a good simulator is difficult to achieve. This work presents a systematic solution to automatically generate a high-fidelity simulator in the Cyber Gym for Intelligent Learning (CyGIL). Through representation learning and continuous learning, CyGIL provides a unified CyOp training environment where an emulated CyGIL-E automatically generates a simulated CyGIL-S. The simulator generation is integrated with the agent training process to further reduce the required agent training time. The agent trained in CyGIL-S is transferrable directly to CyGIL-E showing full transferability to the emulated "real" network. Experimental results are presented to demonstrate the CyGIL training performance. Enabling offline RL, the CyGIL solution presents a promising direction towards sim-to-real for leveraging RL agents in real-world cyber networks.
CyGIL: A Cyber Gym for Training Autonomous Agents over Emulated Network Systems
Sep 07, 2021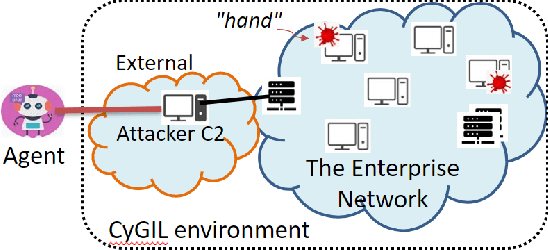
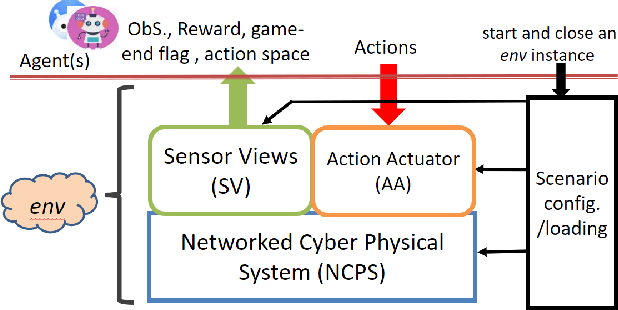
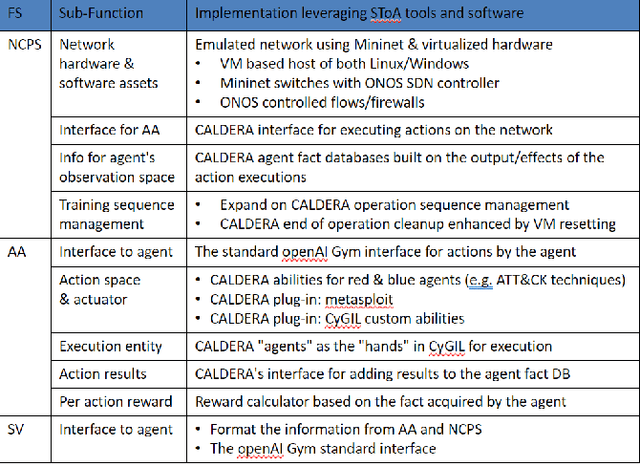
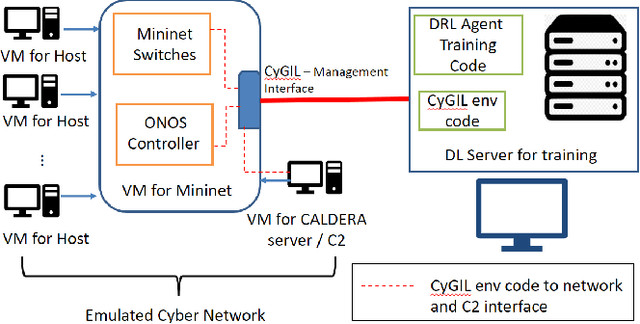
Given the success of reinforcement learning (RL) in various domains, it is promising to explore the application of its methods to the development of intelligent and autonomous cyber agents. Enabling this development requires a representative RL training environment. To that end, this work presents CyGIL: an experimental testbed of an emulated RL training environment for network cyber operations. CyGIL uses a stateless environment architecture and incorporates the MITRE ATT&CK framework to establish a high fidelity training environment, while presenting a sufficiently abstracted interface to enable RL training. Its comprehensive action space and flexible game design allow the agent training to focus on particular advanced persistent threat (APT) profiles, and to incorporate a broad range of potential threats and vulnerabilities. By striking a balance between fidelity and simplicity, it aims to leverage state of the art RL algorithms for application to real-world cyber defence.