 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiGAiVA: Integrated Generative AI and Visual Analytics in a Machine Learning Workflow for Text Classification
Sep 24, 2024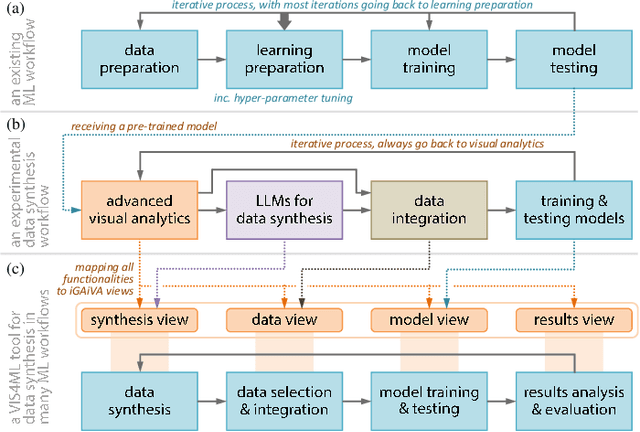
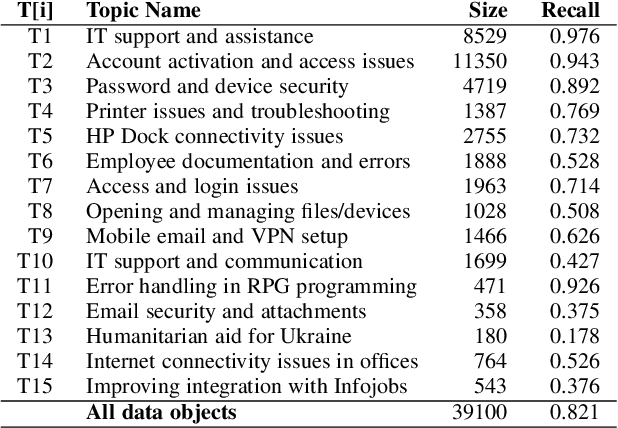
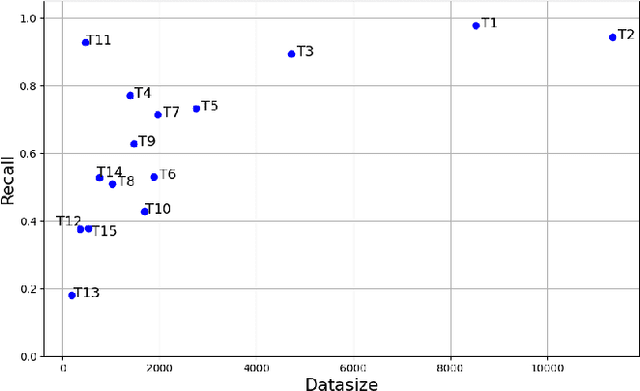

In developing machine learning (ML) models for text classification, one common challenge is that the collected data is often not ideally distributed, especially when new classes are introduced in response to changes of data and tasks. In this paper, we present a solution for using visual analytics (VA) to guide the generation of synthetic data using large language models. As VA enables model developers to identify data-related deficiency, data synthesis can be targeted to address such deficiency. We discuss different types of data deficiency, describe different VA techniques for supporting their identification, and demonstrate the effectiveness of targeted data synthesis in improving model accuracy. In addition, we present a software tool, iGAiVA, which maps four groups of ML tasks into four VA views, integrating generative AI and VA into an ML workflow for developing and improving text classification models.