 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealistic mask generation for matter-wave lithography via machine learning
Jul 15, 2022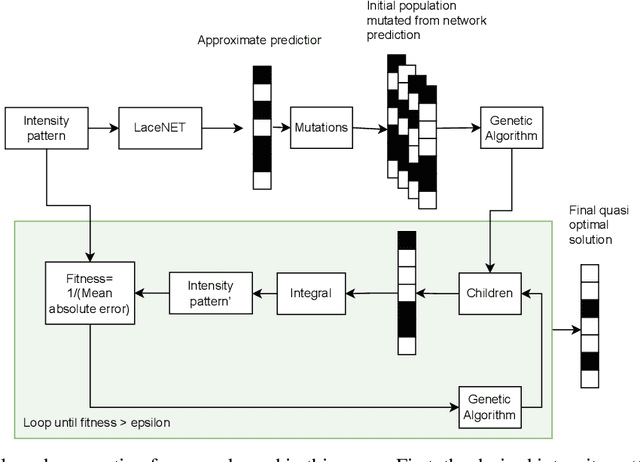
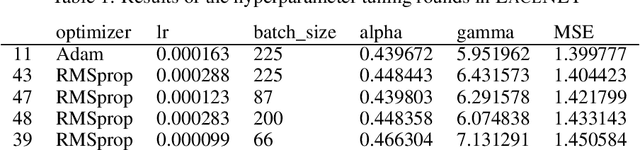
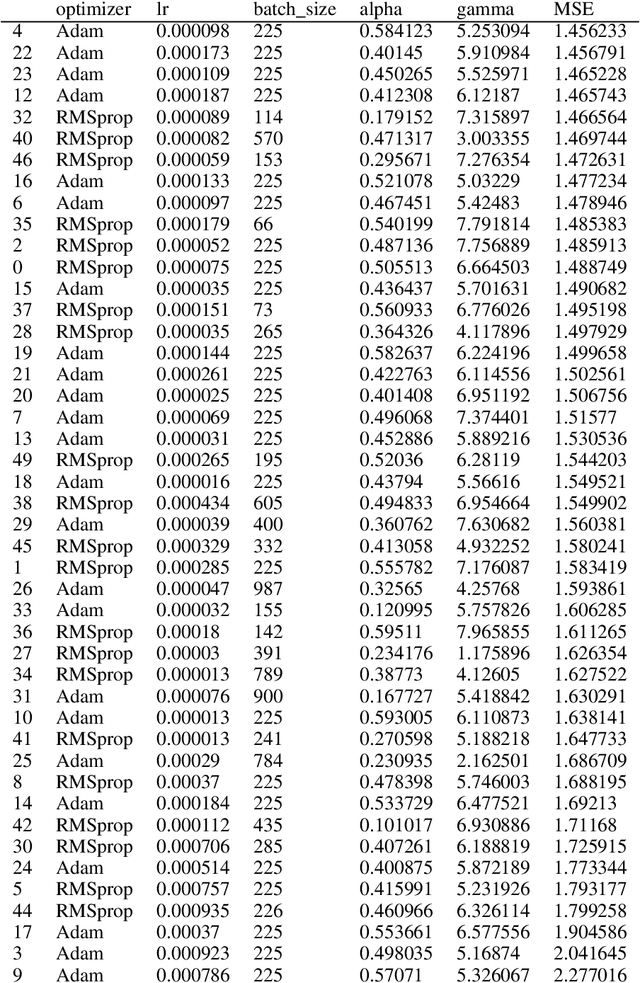
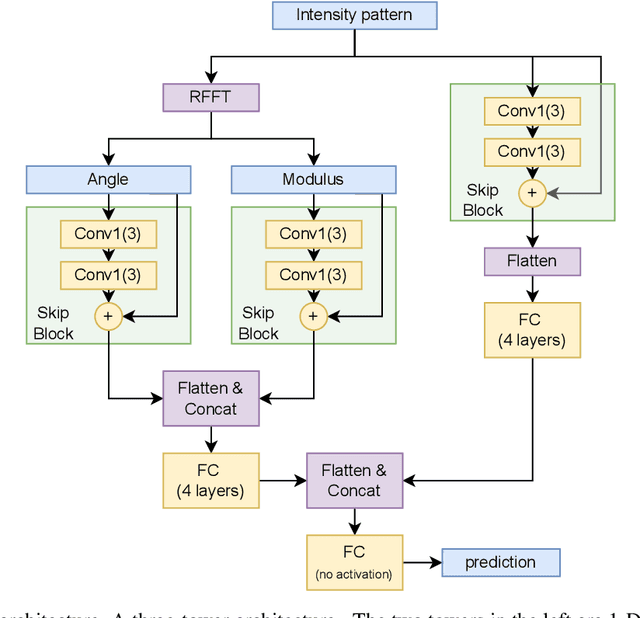
Fast production of large area patterns with nanometre resolution is crucial for the established semiconductor industry and for enabling industrial-scale production of next-generation quantum devices. Metastable atom lithography with binary holography masks has been suggested as a higher resolution/low-cost alternative to the current state of the art: extreme ultraviolet (EUV) lithography. However, it was recently shown that the interaction of the metastable atoms with the mask material (SiN) leads to a strong perturbation of the wavefront, not included in existing mask generation theory, which is based on classical scalar waves. This means that the inverse problem (creating a mask based on the desired pattern) cannot be solved analytically even in 1D. Here we present a machine learning approach to mask generation targeted for metastable atoms. Our algorithm uses a combination of genetic optimisation and deep learning to obtain the mask. A novel deep neural architecture is trained to produce an initial approximation of the mask. This approximation is then used to generate the initial population of the genetic optimisation algorithm that can converge to arbitrary precision. We demonstrate the generation of arbitrary 1D patterns for system dimensions within the Fraunhofer approximation limit.
FooDI-ML: a large multi-language dataset of food, drinks and groceries images and descriptions
Oct 05, 2021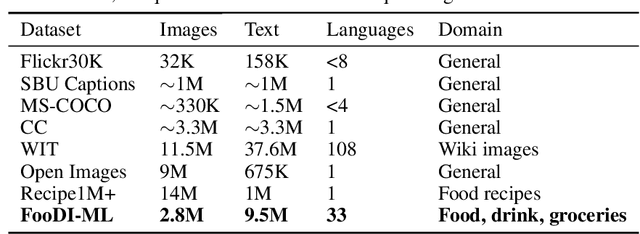

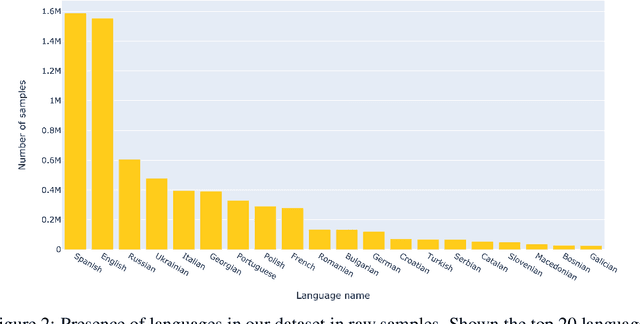
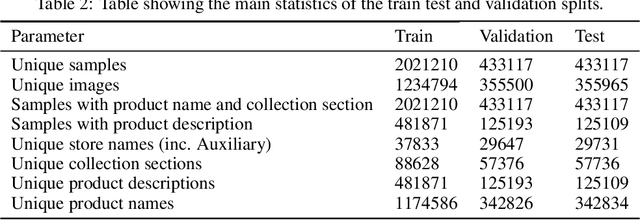
In this paper we introduce the Food Drinks and groceries Images Multi Lingual (FooDI-ML) dataset. This dataset contains over 1.5M unique images and over 9.5M store names, product names descriptions, and collection sections gathered from the Glovo application. The data made available corresponds to food, drinks and groceries products from 37 countries in Europe, the Middle East, Africa and Latin America. The dataset comprehends 33 languages, including 870K samples of languages of countries from Eastern Europe and Western Asia such as Ukrainian and Kazakh, which have been so far underrepresented in publicly available visio-linguistic datasets. The dataset also includes widely spoken languages such as Spanish and English. To assist further research, we include a benchmark over the text-image retrieval task using ADAPT, a SotA existing technique.