 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchitecture-Preserving Provable Repair of Deep Neural Networks
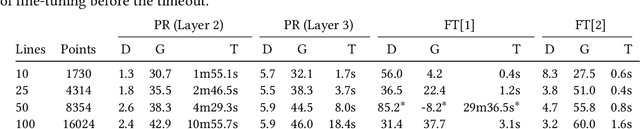
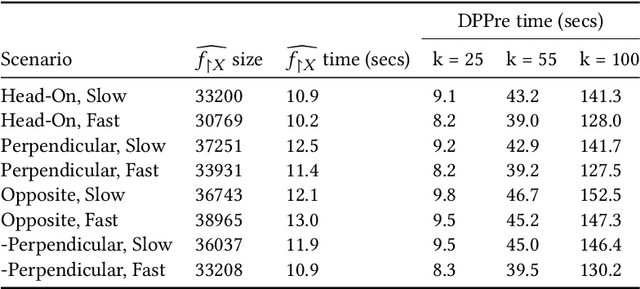
Apr 07, 2023Deep neural networks (DNNs) are becoming increasingly important components of software, and are considered the state-of-the-art solution for a number of problems, such as image recognition. However, DNNs are far from infallible, and incorrect behavior of DNNs can have disastrous real-world consequences. This paper addresses the problem of architecture-preserving V-polytope provable repair of DNNs. A V-polytope defines a convex bounded polytope using its vertex representation. V-polytope provable repair guarantees that the repaired DNN satisfies the given specification on the infinite set of points in the given V-polytope. An architecture-preserving repair only modifies the parameters of the DNN, without modifying its architecture. The repair has the flexibility to modify multiple layers of the DNN, and runs in polynomial time. It supports DNNs with activation functions that have some linear pieces, as well as fully-connected, convolutional, pooling and residual layers. To the best our knowledge, this is the first provable repair approach that has all of these features. We implement our approach in a tool called APRNN. Using MNIST, ImageNet, and ACAS Xu DNNs, we show that it has better efficiency, scalability, and generalization compared to PRDNN and REASSURE, prior provable repair methods that are not architecture preserving.
Provable Repair of Deep Neural Networks
Apr 25, 2021

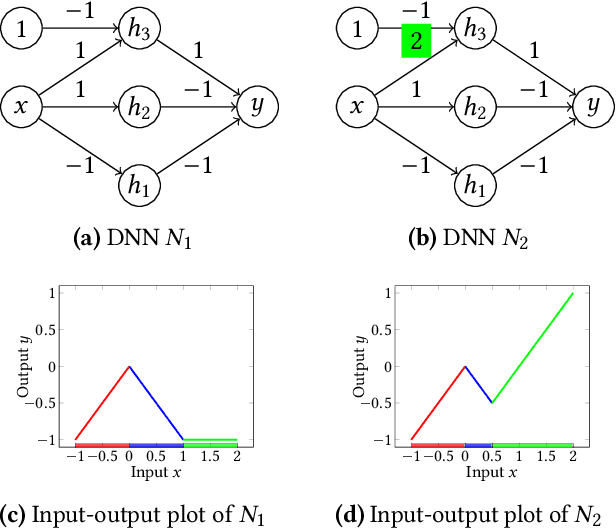
Deep Neural Networks (DNNs) have grown in popularity over the past decade and are now being used in safety-critical domains such as aircraft collision avoidance. This has motivated a large number of techniques for finding unsafe behavior in DNNs. In contrast, this paper tackles the problem of correcting a DNN once unsafe behavior is found. We introduce the provable repair problem, which is the problem of repairing a network N to construct a new network N' that satisfies a given specification. If the safety specification is over a finite set of points, our Provable Point Repair algorithm can find a provably minimal repair satisfying the specification, regardless of the activation functions used. For safety specifications addressing convex polytopes containing infinitely many points, our Provable Polytope Repair algorithm can find a provably minimal repair satisfying the specification for DNNs using piecewise-linear activation functions. The key insight behind both of these algorithms is the introduction of a Decoupled DNN architecture, which allows us to reduce provable repair to a linear programming problem. Our experimental results demonstrate the efficiency and effectiveness of our Provable Repair algorithms on a variety of challenging tasks.
SyReNN: A Tool for Analyzing Deep Neural Networks
Jan 09, 2021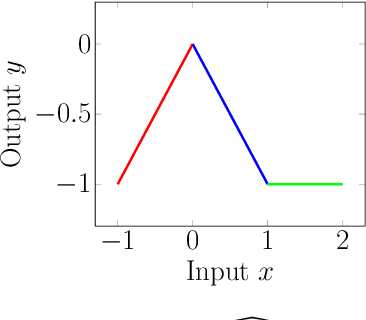
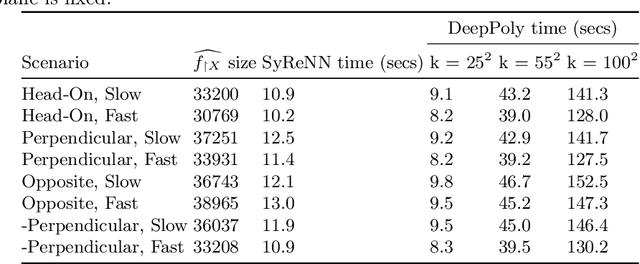
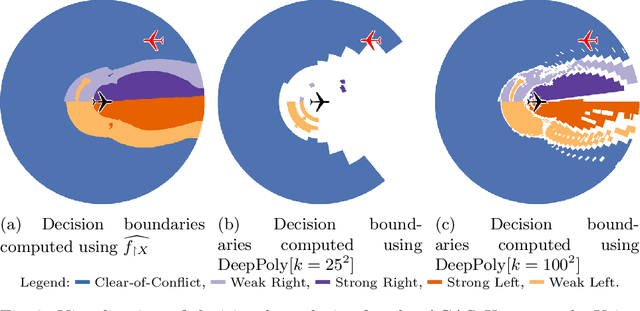
Deep Neural Networks (DNNs) are rapidly gaining popularity in a variety of important domains. Formally, DNNs are complicated vector-valued functions which come in a variety of sizes and applications. Unfortunately, modern DNNs have been shown to be vulnerable to a variety of attacks and buggy behavior. This has motivated recent work in formally analyzing the properties of such DNNs. This paper introduces SyReNN, a tool for understanding and analyzing a DNN by computing its symbolic representation. The key insight is to decompose the DNN into linear functions. Our tool is designed for analyses using low-dimensional subsets of the input space, a unique design point in the space of DNN analysis tools. We describe the tool and the underlying theory, then evaluate its use and performance on three case studies: computing Integrated Gradients, visualizing a DNN's decision boundaries, and patching a DNN.
Analogy-Making as a Core Primitive in the Software Engineering Toolbox
Sep 14, 2020


An analogy is an identification of structural similarities and correspondences between two objects. Computational models of analogy making have been studied extensively in the field of cognitive science to better understand high-level human cognition. For instance, Melanie Mitchell and Douglas Hofstadter sought to better understand high-level perception by developing the Copycat algorithm for completing analogies between letter sequences. In this paper, we argue that analogy making should be seen as a core primitive in software engineering. We motivate this argument by showing how complex software engineering problems such as program understanding and source-code transformation learning can be reduced to an instance of the analogy-making problem. We demonstrate this idea using Sifter, a new analogy-making algorithm suitable for software engineering applications that adapts and extends ideas from Copycat. In particular, Sifter reduces analogy-making to searching for a sequence of update rule applications. Sifter uses a novel representation for mathematical structures capable of effectively representing the wide variety of information embedded in software. We conclude by listing major areas of future work for Sifter and analogy-making in software engineering.
Abstract Neural Networks
Sep 11, 2020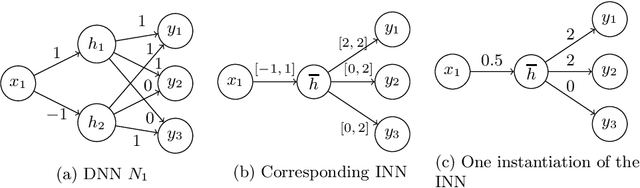
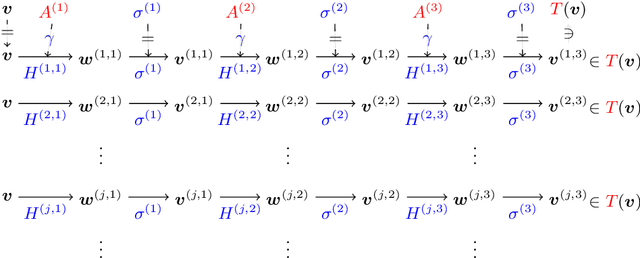
Deep Neural Networks (DNNs) are rapidly being applied to safety-critical domains such as drone and airplane control, motivating techniques for verifying the safety of their behavior. Unfortunately, DNN verification is NP-hard, with current algorithms slowing exponentially with the number of nodes in the DNN. This paper introduces the notion of Abstract Neural Networks (ANNs), which can be used to soundly overapproximate DNNs while using fewer nodes. An ANN is like a DNN except weight matrices are replaced by values in a given abstract domain. We present a framework parameterized by the abstract domain and activation functions used in the DNN that can be used to construct a corresponding ANN. We present necessary and sufficient conditions on the DNN activation functions for the constructed ANN to soundly over-approximate the given DNN. Prior work on DNN abstraction was restricted to the interval domain and ReLU activation function. Our framework can be instantiated with other abstract domains such as octagons and polyhedra, as well as other activation functions such as Leaky ReLU, Sigmoid, and Hyperbolic Tangent.
A Symbolic Neural Network Representation and its Application to Understanding, Verifying, and Patching Networks
Aug 20, 2019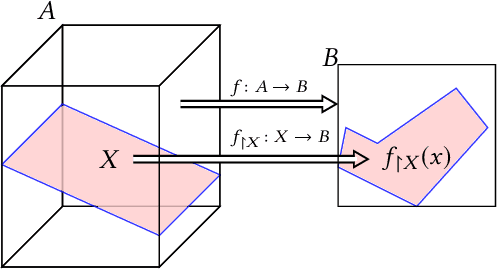
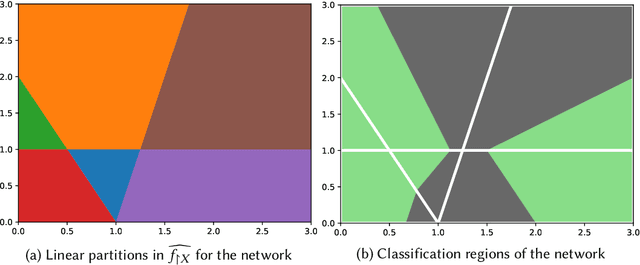

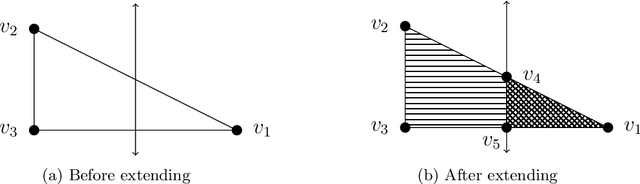
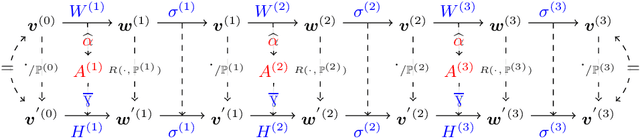
Analysis and manipulation of trained neural networks is a challenging and important problem. We propose a symbolic representation for piecewise-linear neural networks and discuss its efficient computation. With this representation, one can translate the problem of analyzing a complex neural network into that of analyzing a finite set of affine functions. We demonstrate the use of this representation for three applications. First, we apply the symbolic representation to computing weakest preconditions on network inputs, which we use to exactly visualize the advisories made by a network meant to operate an aircraft collision avoidance system. Second, we use the symbolic representation to compute strongest postconditions on the network outputs, which we use to perform bounded model checking on standard neural network controllers. Finally, we show how the symbolic representation can be combined with a new form of neural network to perform patching; i.e., correct user-specified behavior of the network.
Computing Linear Restrictions of Neural Networks
Aug 17, 2019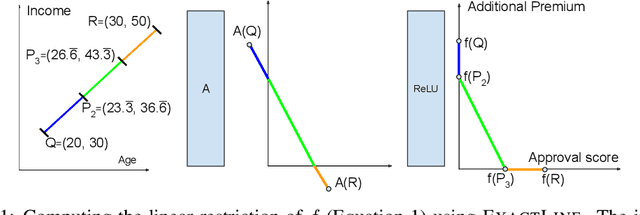
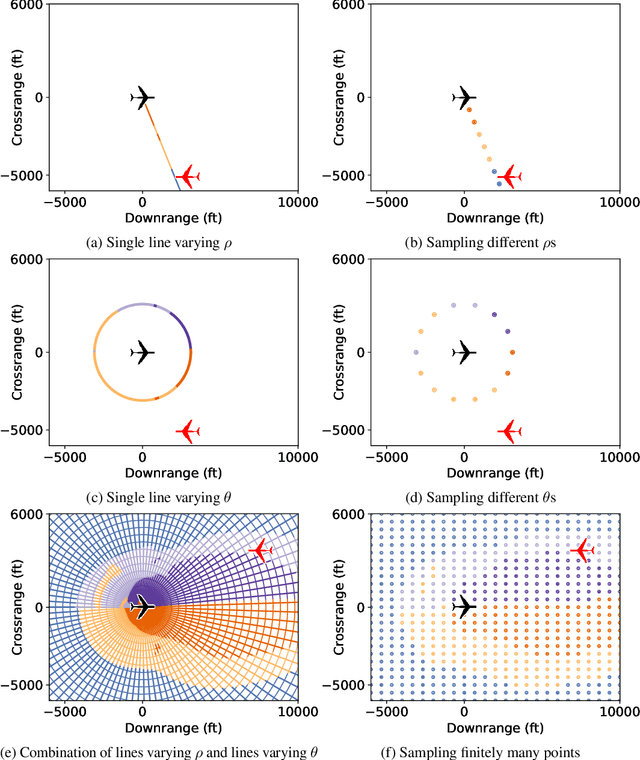


A linear restriction of a function is the same function with its domain restricted to points on a given line. This paper addresses the problem of computing a succinct representation for a linear restriction of a piecewise-linear neural network. This primitive, which we call ExactLine, allows us to exactly characterize the result of applying the network to all of the infinitely many points on a line. In particular, ExactLine computes a partitioning of the given input line segment such that the network is affine on each partition. We present an efficient algorithm for computing ExactLine for networks that use ReLU, MaxPool, batch normalization, fully-connected, convolutional, and other layers, along with several applications. First, we show how to exactly determine decision boundaries of an ACAS Xu neural network, providing significantly improved confidence in the results compared to prior work that sampled finitely many points in the input space. Next, we demonstrate how to exactly compute integrated gradients, which are commonly used for neural network attributions, allowing us to show that the prior heuristic-based methods had relative errors of 25-45% and show that a better sampling method can achieve higher accuracy with less computation. Finally, we use ExactLine to empirically falsify the core assumption behind a well-known hypothesis about adversarial examples, and in the process identify interesting properties of adversarially-trained networks.