 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Algorithms in Statistical Modelling Bridging Theory and Application
Nov 07, 2025It involves the completely novel ways of integrating ML algorithms with traditional statistical modelling that has changed the way we analyze data, do predictive analytics or make decisions in the fields of the data. In this paper, we study some ML and statistical model connections to understand ways in which some modern ML algorithms help 'enrich' conventional models; we demonstrate how new algorithms improve performance, scale, flexibility and robustness of the traditional models. It shows that the hybrid models are of great improvement in predictive accuracy, robustness, and interpretability
* 9 Pages, 4 Figures
"Previously on ..." From Recaps to Story Summarization
May 19, 2024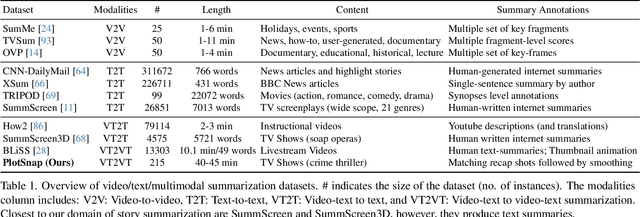
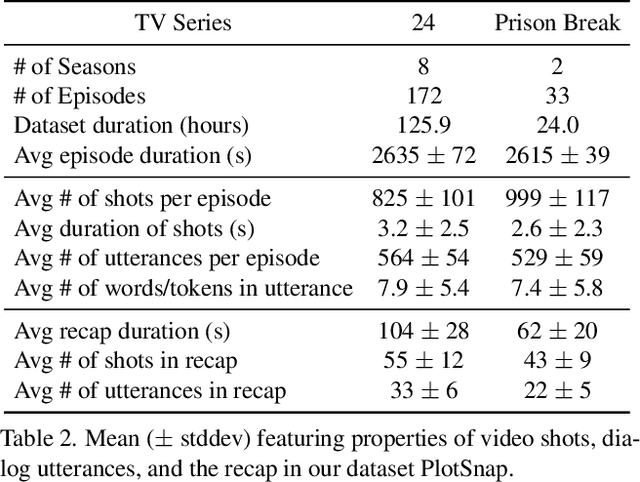
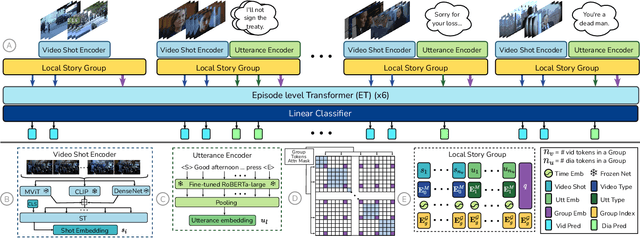
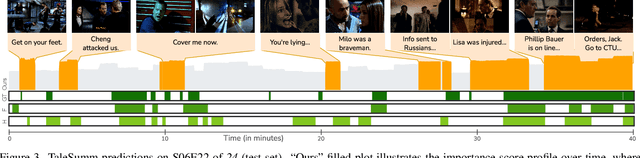
We introduce multimodal story summarization by leveraging TV episode recaps - short video sequences interweaving key story moments from previous episodes to bring viewers up to speed. We propose PlotSnap, a dataset featuring two crime thriller TV shows with rich recaps and long episodes of 40 minutes. Story summarization labels are unlocked by matching recap shots to corresponding sub-stories in the episode. We propose a hierarchical model TaleSumm that processes entire episodes by creating compact shot and dialog representations, and predicts importance scores for each video shot and dialog utterance by enabling interactions between local story groups. Unlike traditional summarization, our method extracts multiple plot points from long videos. We present a thorough evaluation on story summarization, including promising cross-series generalization. TaleSumm also shows good results on classic video summarization benchmarks.
How you feelin'? Learning Emotions and Mental States in Movie Scenes
Apr 12, 2023Movie story analysis requires understanding characters' emotions and mental states. Towards this goal, we formulate emotion understanding as predicting a diverse and multi-label set of emotions at the level of a movie scene and for each character. We propose EmoTx, a multimodal Transformer-based architecture that ingests videos, multiple characters, and dialog utterances to make joint predictions. By leveraging annotations from the MovieGraphs dataset, we aim to predict classic emotions (e.g. happy, angry) and other mental states (e.g. honest, helpful). We conduct experiments on the most frequently occurring 10 and 25 labels, and a mapping that clusters 181 labels to 26. Ablation studies and comparison against adapted state-of-the-art emotion recognition approaches shows the effectiveness of EmoTx. Analyzing EmoTx's self-attention scores reveals that expressive emotions often look at character tokens while other mental states rely on video and dialog cues.
Multi-Label Classification on Remote-Sensing Images
Jan 06, 2022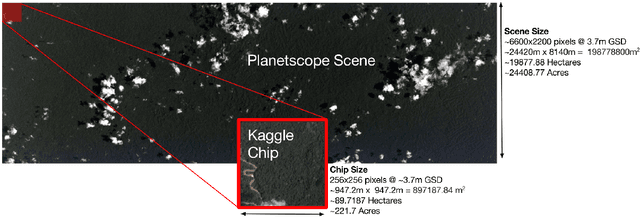

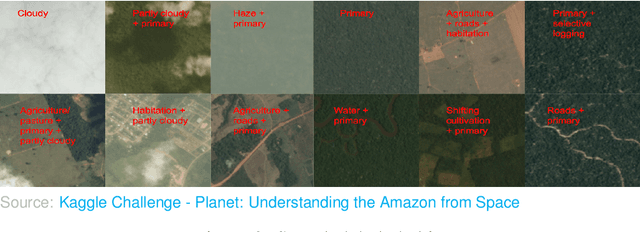

Acquiring information on large areas on the earth's surface through satellite cameras allows us to see much more than we can see while standing on the ground. This assists us in detecting and monitoring the physical characteristics of an area like land-use patterns, atmospheric conditions, forest cover, and many unlisted aspects. The obtained images not only keep track of continuous natural phenomena but are also crucial in tackling the global challenge of severe deforestation. Among which Amazon basin accounts for the largest share every year. Proper data analysis would help limit detrimental effects on the ecosystem and biodiversity with a sustainable healthy atmosphere. This report aims to label the satellite image chips of the Amazon rainforest with atmospheric and various classes of land cover or land use through different machine learning and superior deep learning models. Evaluation is done based on the F2 metric, while for loss function, we have both sigmoid cross-entropy as well as softmax cross-entropy. Images are fed indirectly to the machine learning classifiers after only features are extracted using pre-trained ImageNet architectures. Whereas for deep learning models, ensembles of fine-tuned ImageNet pre-trained models are used via transfer learning. Our best score was achieved so far with the F2 metric is 0.927.