 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards noise robust trigger-word detection with contrastive learning pre-task for fast on-boarding of new trigger-words
Nov 06, 2021
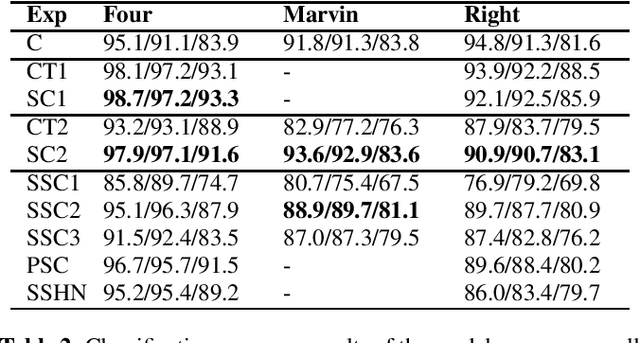
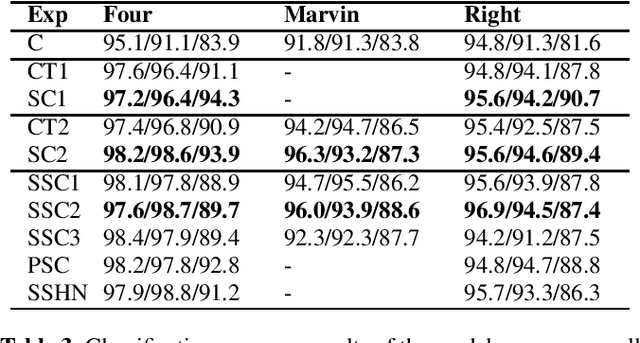
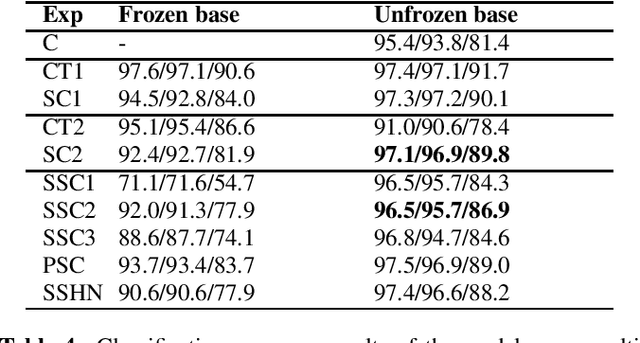
Trigger-word detection plays an important role as the entry point of user's communication with voice assistants. But supporting a particular word as a trigger-word involves huge amount of data collection, augmentation and labelling for that word. This makes supporting new trigger-words a tedious and time consuming process. To combat this, we explore the use of contrastive learning as a pre-training task that helps the detection model to generalize to different words and noise conditions. We explore supervised contrastive techniques and also propose a self-supervised technique using chunked words from long sentence audios. We show that the contrastive pre-training techniques have comparable results to a traditional classification pre-training on new trigger words with less data availability.
Countering Inconsistent Labelling by Google's Vision API for Rotated Images
Nov 17, 2019

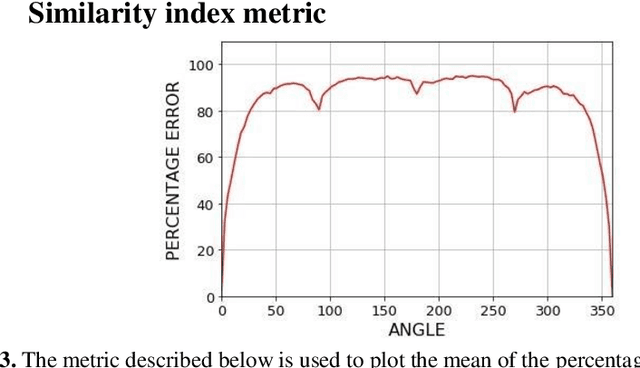
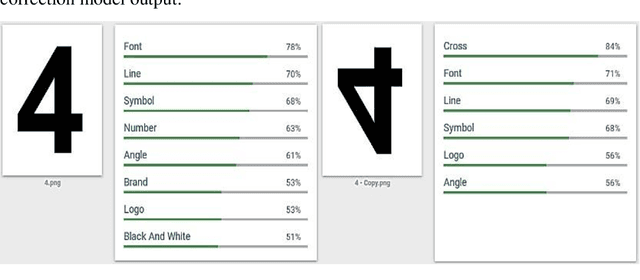
Google's Vision API analyses images and provides a variety of output predictions, one such type is context-based labelling. In this paper, it is shown that adversarial examples that cause incorrect label prediction and spoofing can be generated by rotating the images. Due to the black-boxed nature of the API, a modular context-based pre-processing pipeline is proposed consisting of a Res-Net50 model, that predicts the angle by which the image must be rotated to correct its orientation. The pipeline successfully performs the correction whilst maintaining the image's resolution and feeds it to the API which generates labels similar to the original correctly oriented image and using a Percentage Error metric, the performance of the corrected images as compared to its rotated counter-parts is found to be significantly higher. These observations imply that the API can benefit from such a pre-processing pipeline to increase robustness to rotational perturbances.