 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards noise robust trigger-word detection with contrastive learning pre-task for fast on-boarding of new trigger-words
Paper and Code
Nov 06, 2021
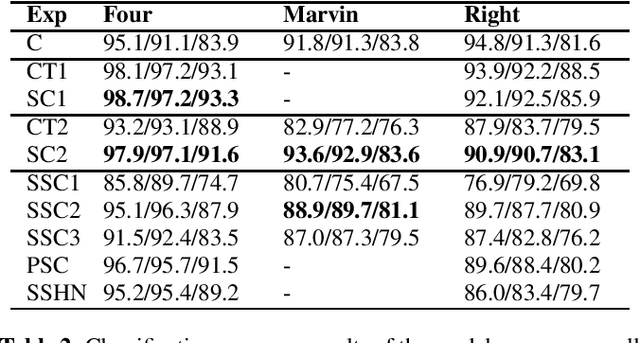
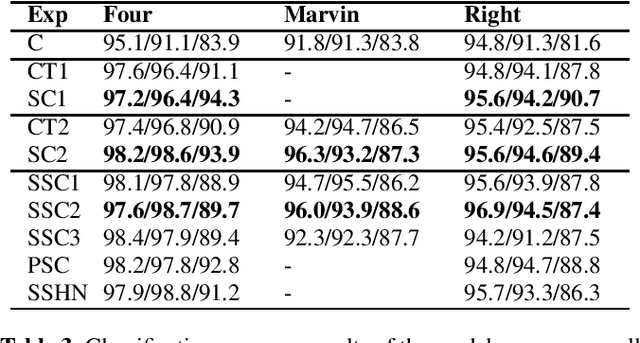
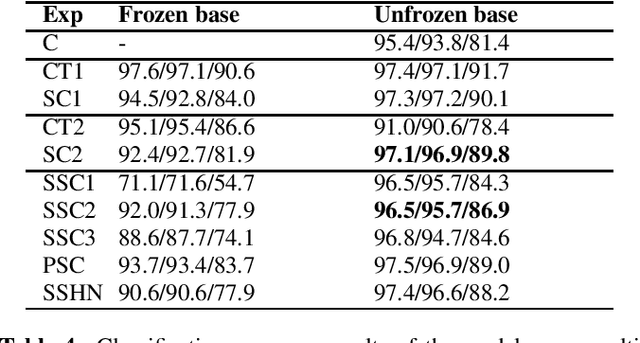
Trigger-word detection plays an important role as the entry point of user's communication with voice assistants. But supporting a particular word as a trigger-word involves huge amount of data collection, augmentation and labelling for that word. This makes supporting new trigger-words a tedious and time consuming process. To combat this, we explore the use of contrastive learning as a pre-training task that helps the detection model to generalize to different words and noise conditions. We explore supervised contrastive techniques and also propose a self-supervised technique using chunked words from long sentence audios. We show that the contrastive pre-training techniques have comparable results to a traditional classification pre-training on new trigger words with less data availability.