 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithful and Plausible Natural Language Explanations for Image Classification: A Pipeline Approach
Jul 30, 2024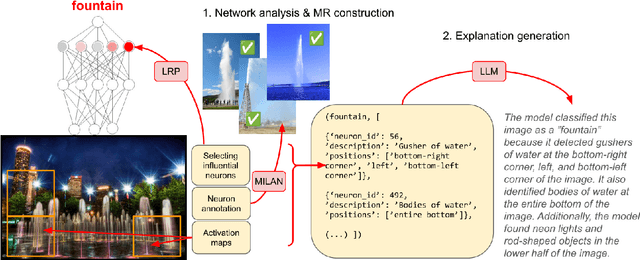
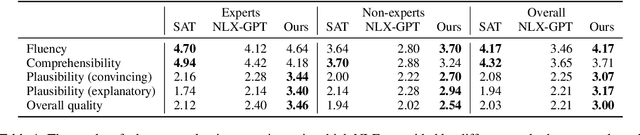
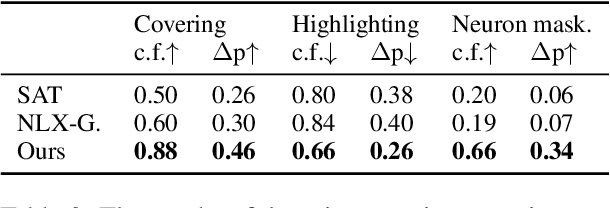
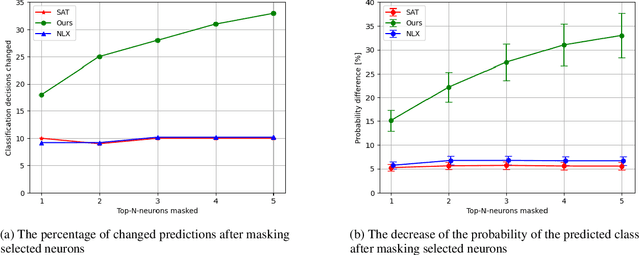
Existing explanation methods for image classification struggle to provide faithful and plausible explanations. This paper addresses this issue by proposing a post-hoc natural language explanation method that can be applied to any CNN-based classifier without altering its training process or affecting predictive performance. By analysing influential neurons and the corresponding activation maps, the method generates a faithful description of the classifier's decision process in the form of a structured meaning representation, which is then converted into text by a language model. Through this pipeline approach, the generated explanations are grounded in the neural network architecture, providing accurate insight into the classification process while remaining accessible to non-experts. Experimental results show that the NLEs constructed by our method are significantly more plausible and faithful. In particular, user interventions in the neural network structure (masking of neurons) are three times more effective than the baselines.