 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Corruption Robustness: Inductive Biases in Vision Transformers and MLP-Mixers
Jul 03, 2021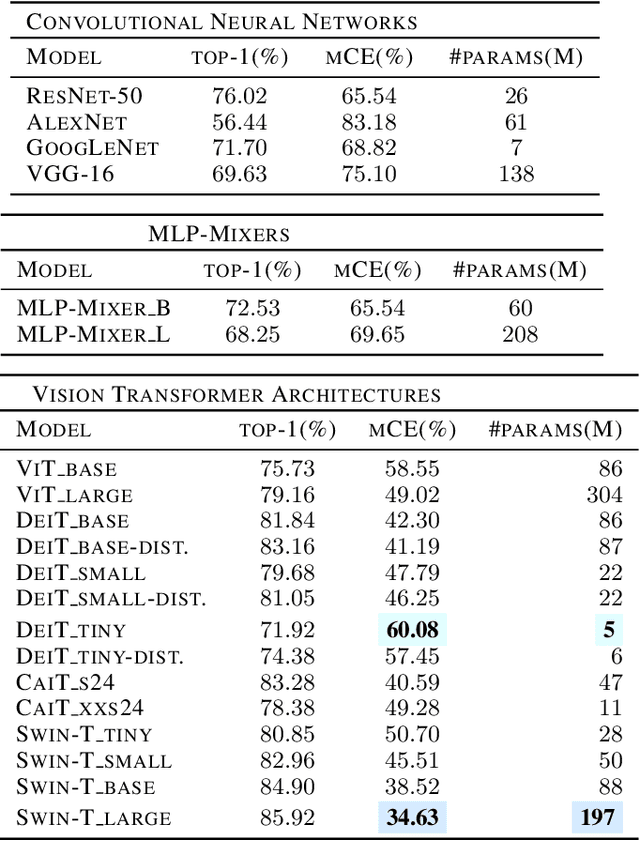
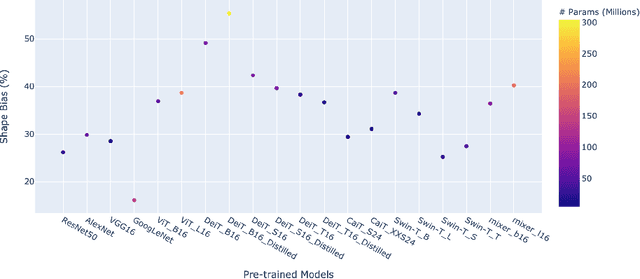
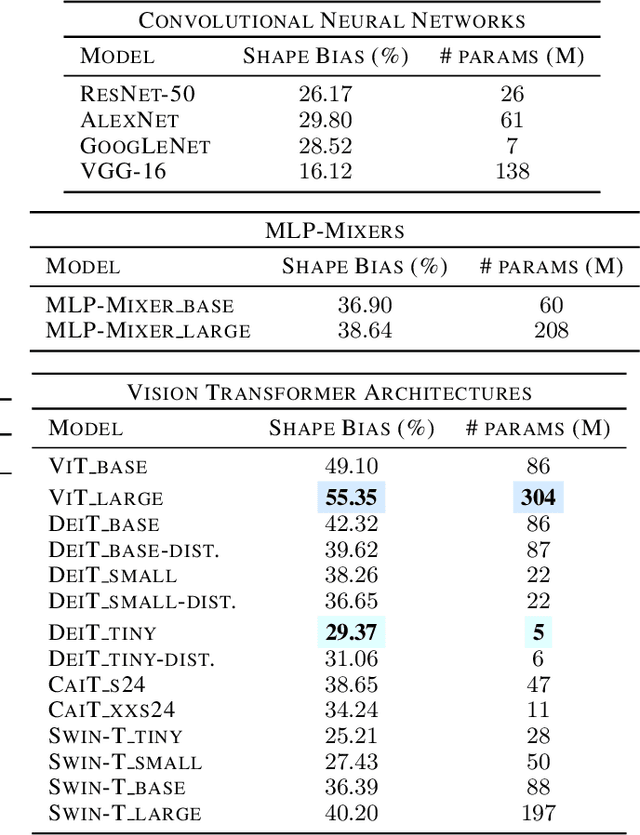
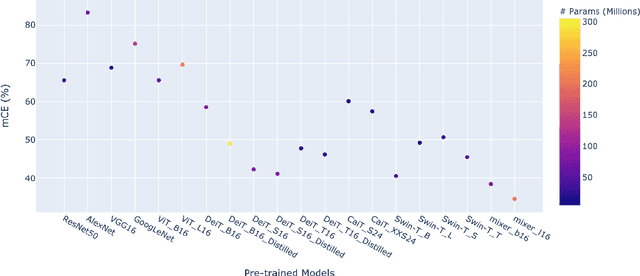
Recently, vision transformers and MLP-based models have been developed in order to address some of the prevalent weaknesses in convolutional neural networks. Due to the novelty of transformers being used in this domain along with the self-attention mechanism, it remains unclear to what degree these architectures are robust to corruptions. Despite some works proposing that data augmentation remains essential for a model to be robust against corruptions, we propose to explore the impact that the architecture has on corruption robustness. We find that vision transformer architectures are inherently more robust to corruptions than the ResNet-50 and MLP-Mixers. We also find that vision transformers with 5 times fewer parameters than a ResNet-50 have more shape bias. Our code is available to reproduce.