 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Forest-Supervised Manifold Alignment
Nov 18, 2024


Manifold alignment is a type of data fusion technique that creates a shared low-dimensional representation of data collected from multiple domains, enabling cross-domain learning and improved performance in downstream tasks. This paper presents an approach to manifold alignment using random forests as a foundation for semi-supervised alignment algorithms, leveraging the model's inherent strengths. We focus on enhancing two recently developed alignment graph-based by integrating class labels through geometry-preserving proximities derived from random forests. These proximities serve as a supervised initialization for constructing cross-domain relationships that maintain local neighborhood structures, thereby facilitating alignment. Our approach addresses a common limitation in manifold alignment, where existing methods often fail to generate embeddings that capture sufficient information for downstream classification. By contrast, we find that alignment models that use random forest proximities or class-label information achieve improved accuracy on downstream classification tasks, outperforming single-domain baselines. Experiments across multiple datasets show that our method typically enhances cross-domain feature integration and predictive performance, suggesting that random forest proximities offer a practical solution for tasks requiring multimodal data alignment.
Graph Integration for Diffusion-Based Manifold Alignment
Oct 30, 2024


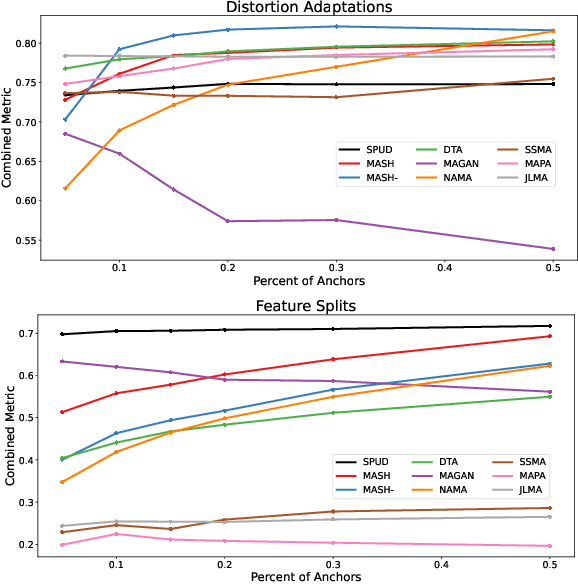
Data from individual observations can originate from various sources or modalities but are often intrinsically linked. Multimodal data integration can enrich information content compared to single-source data. Manifold alignment is a form of data integration that seeks a shared, underlying low-dimensional representation of multiple data sources that emphasizes similarities between alternative representations of the same entities. Semi-supervised manifold alignment relies on partially known correspondences between domains, either through shared features or through other known associations. In this paper, we introduce two semi-supervised manifold alignment methods. The first method, Shortest Paths on the Union of Domains (SPUD), forms a unified graph structure using known correspondences to establish graph edges. By learning inter-domain geodesic distances, SPUD creates a global, multi-domain structure. The second method, MASH (Manifold Alignment via Stochastic Hopping), learns local geometry within each domain and forms a joint diffusion operator using known correspondences to iteratively learn new inter-domain correspondences through a random-walk approach. Through the diffusion process, MASH forms a coupling matrix that links heterogeneous domains into a unified structure. We compare SPUD and MASH with existing semi-supervised manifold alignment methods and show that they outperform competing methods in aligning true correspondences and cross-domain classification. In addition, we show how these methods can be applied to transfer label information between domains.