 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJambu: A historical linguistic database for South Asian languages
Jun 05, 2023We introduce Jambu, a cognate database of South Asian languages which unifies dozens of previous sources in a structured and accessible format. The database includes 287k lemmata from 602 lects, grouped together in 23k sets of cognates. We outline the data wrangling necessary to compile the dataset and train neural models for reflex prediction on the Indo-Aryan subset of the data. We hope that Jambu is an invaluable resource for all historical linguists and Indologists, and look towards further improvement and expansion of the database.
Computational historical linguistics and language diversity in South Asia
Mar 23, 2022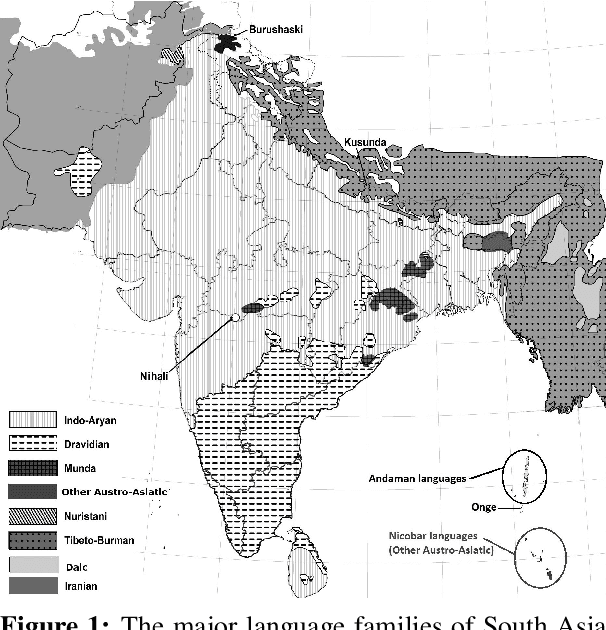
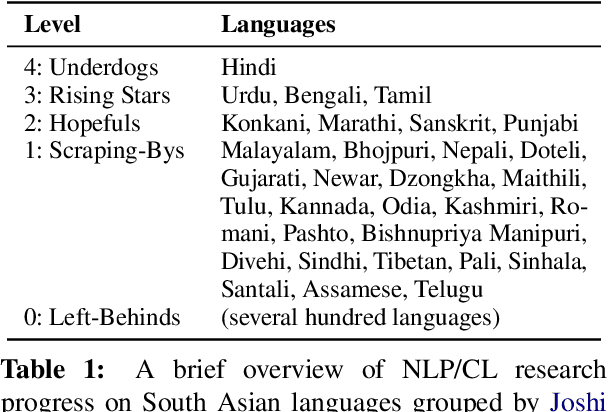
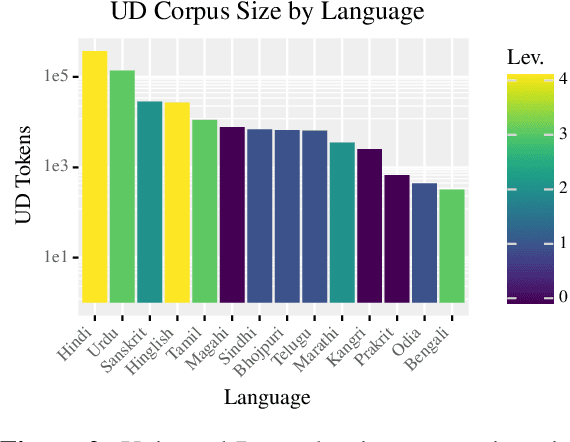
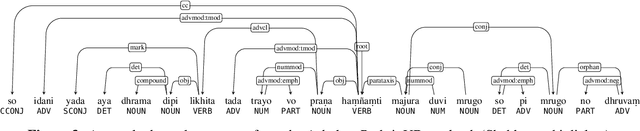
South Asia is home to a plethora of languages, many of which severely lack access to new language technologies. This linguistic diversity also results in a research environment conducive to the study of comparative, contact, and historical linguistics -- fields which necessitate the gathering of extensive data from many languages. We claim that data scatteredness (rather than scarcity) is the primary obstacle in the development of South Asian language technology, and suggest that the study of language history is uniquely aligned with surmounting this obstacle. We review recent developments in and at the intersection of South Asian NLP and historical-comparative linguistics, describing our and others' current efforts in this area. We also offer new strategies towards breaking the data barrier.
For the Purpose of Curry: A UD Treebank for Ashokan Prakrit
Dec 11, 2021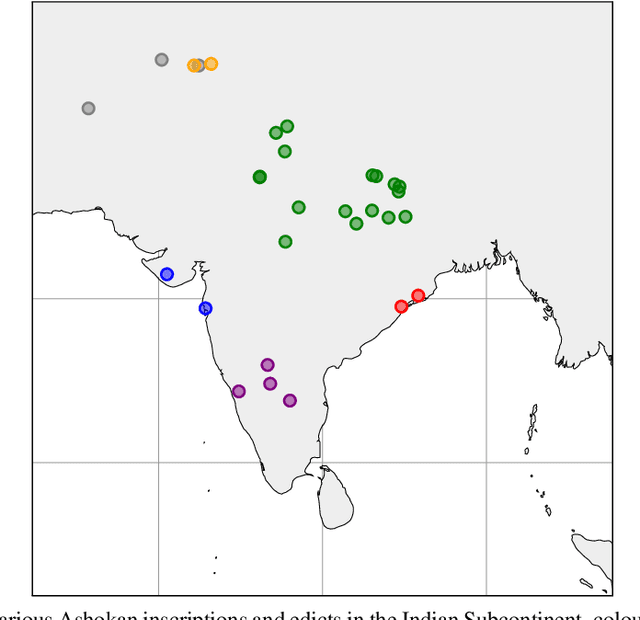
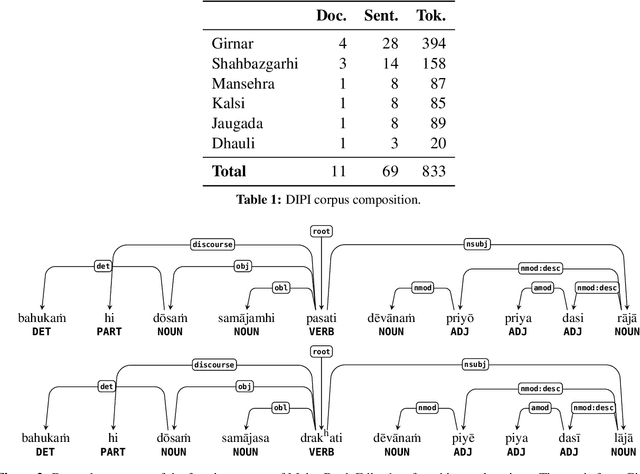
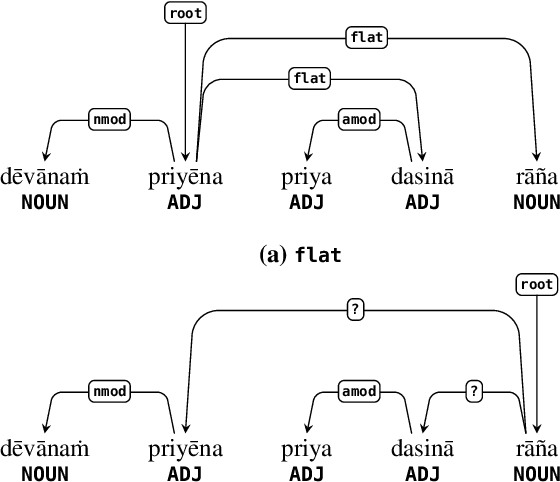
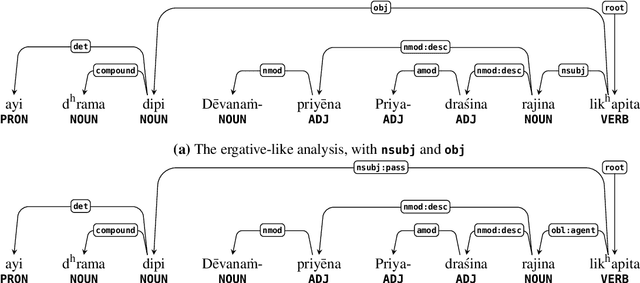
We present the first linguistically annotated treebank of Ashokan Prakrit, an early Middle Indo-Aryan dialect continuum attested through Emperor Ashoka Maurya's 3rd century BCE rock and pillar edicts. For annotation, we used the multilingual Universal Dependencies (UD) formalism, following recent UD work on Sanskrit and other Indo-Aryan languages. We touch on some interesting linguistic features that posed issues in annotation: regnal names and other nominal compounds, "proto-ergative" participial constructions, and possible grammaticalizations evidenced by sandhi (phonological assimilation across morpheme boundaries). Eventually, we plan for a complete annotation of all attested Ashokan texts, towards the larger goals of improving UD coverage of different diachronic stages of Indo-Aryan and studying language change in Indo-Aryan using computational methods.
Bhā$\unicode{x1E63}$ācitra: Visualising the dialect geography of South Asia
Jun 08, 2021
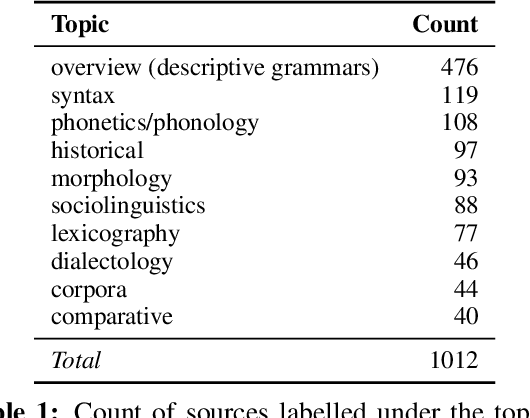
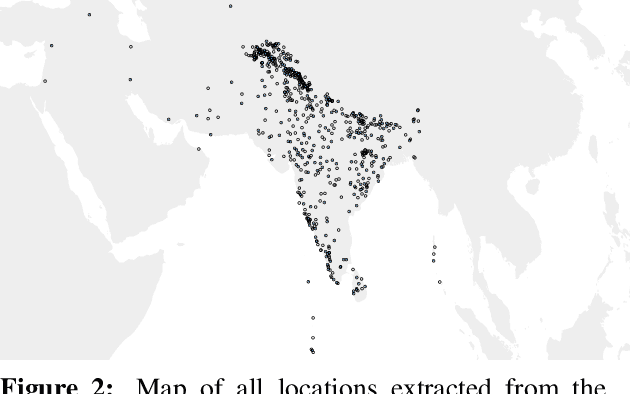
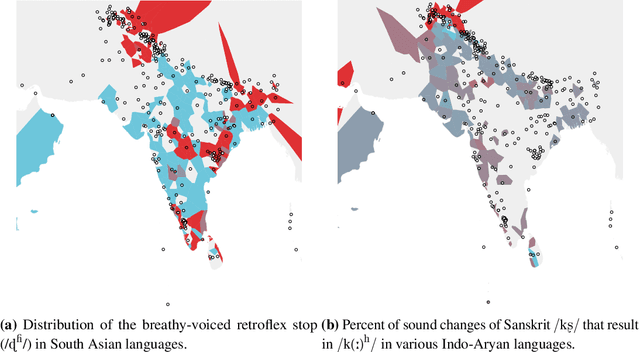
We present Bh\=a$\unicode{x1E63}$\=acitra, a dialect mapping system for South Asia built on a database of linguistic studies of languages of the region annotated for topic and location data. We analyse language coverage and look towards applications to typology by visualising example datasets. The application is not only meant to be useful for feature mapping, but also serves as a new kind of interactive bibliography for linguists of South Asian languages.