 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational historical linguistics and language diversity in South Asia
Paper and Code
Mar 23, 2022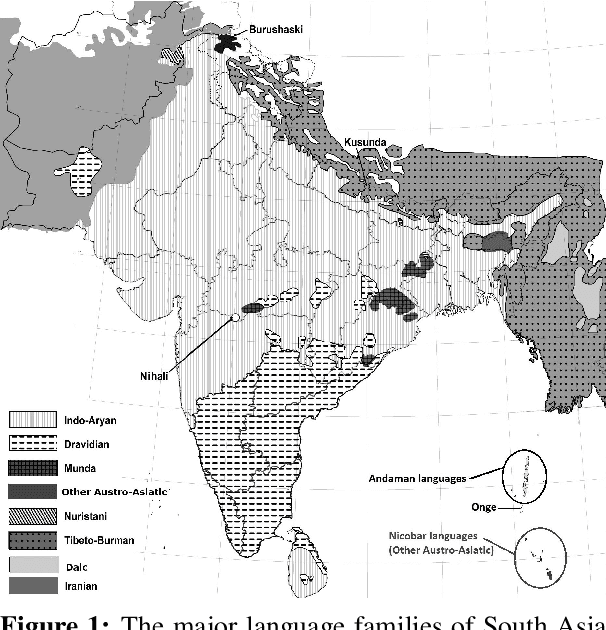
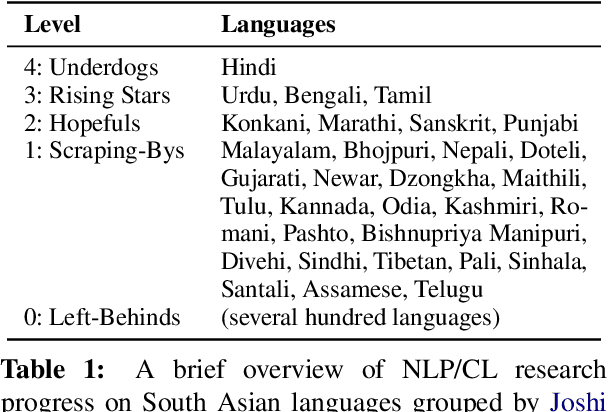
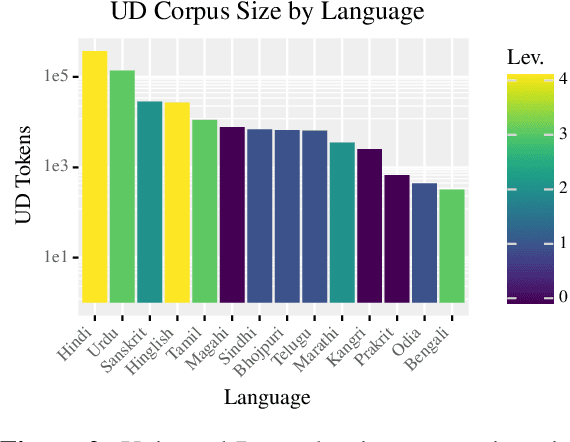
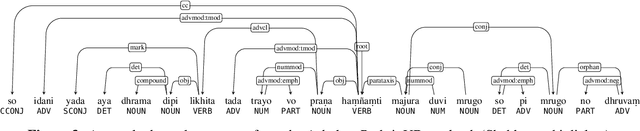
South Asia is home to a plethora of languages, many of which severely lack access to new language technologies. This linguistic diversity also results in a research environment conducive to the study of comparative, contact, and historical linguistics -- fields which necessitate the gathering of extensive data from many languages. We claim that data scatteredness (rather than scarcity) is the primary obstacle in the development of South Asian language technology, and suggest that the study of language history is uniquely aligned with surmounting this obstacle. We review recent developments in and at the intersection of South Asian NLP and historical-comparative linguistics, describing our and others' current efforts in this area. We also offer new strategies towards breaking the data barrier.