 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Disparity Compensation for Efficient Fair Ranking
Jul 25, 2023Ranking functions that are used in decision systems often produce disparate results for different populations because of bias in the underlying data. Addressing, and compensating for, these disparate outcomes is a critical problem for fair decision-making. Recent compensatory measures have mostly focused on opaque transformations of the ranking functions to satisfy fairness guarantees or on the use of quotas or set-asides to guarantee a minimum number of positive outcomes to members of underrepresented groups. In this paper we propose easily explainable data-driven compensatory measures for ranking functions. Our measures rely on the generation of bonus points given to members of underrepresented groups to address disparity in the ranking function. The bonus points can be set in advance, and can be combined, allowing for considering the intersections of representations and giving better transparency to stakeholders. We propose efficient sampling-based algorithms to calculate the number of bonus points to minimize disparity. We validate our algorithms using real-world school admissions and recidivism datasets, and compare our results with that of existing fair ranking algorithms.
Merging datasets through deep learning
Sep 05, 2018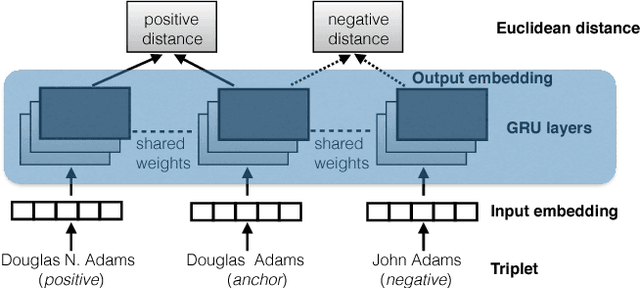
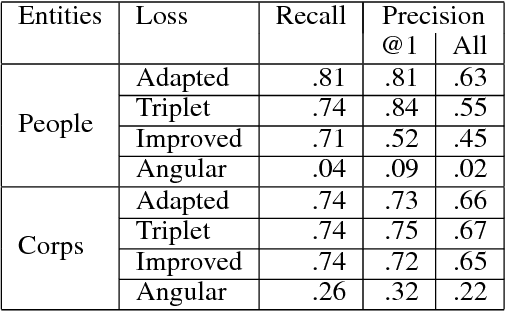
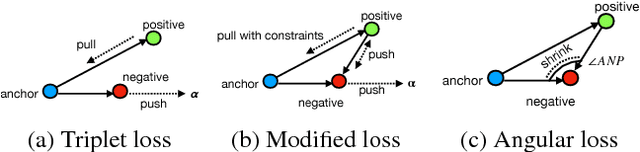
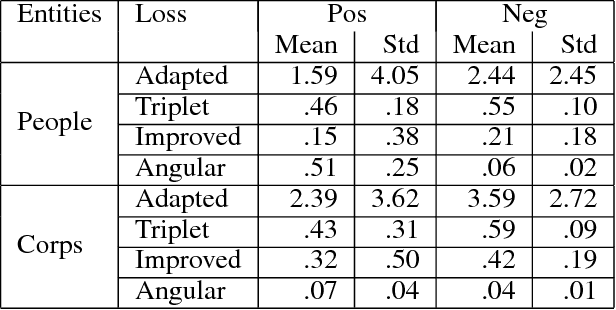
Merging datasets is a key operation for data analytics. A frequent requirement for merging is joining across columns that have different surface forms for the same entity (e.g., the name of a person might be represented as "Douglas Adams" or "Adams, Douglas"). Similarly, ontology alignment can require recognizing distinct surface forms of the same entity, especially when ontologies are independently developed. However, data management systems are currently limited to performing merges based on string equality, or at best using string similarity. We propose an approach to performing merges based on deep learning models. Our approach depends on (a) creating a deep learning model that maps surface forms of an entity into a set of vectors such that alternate forms for the same entity are closest in vector space, (b) indexing these vectors using a nearest neighbors algorithm to find the forms that can be potentially joined together. To build these models, we had to adapt techniques from metric learning due to the characteristics of the data; specifically we describe novel sample selection techniques and loss functions that work for this problem. To evaluate our approach, we used Wikidata as ground truth and built models from datasets with approximately 1.1M people's names (200K identities) and 130K company names (70K identities). We developed models that allow for joins with precision@1 of .75-.81 and recall of .74-.81. We make the models available for aligning people or companies across multiple datasets.