Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectrogram Feature Losses for Music Source Separation
Jan 18, 2019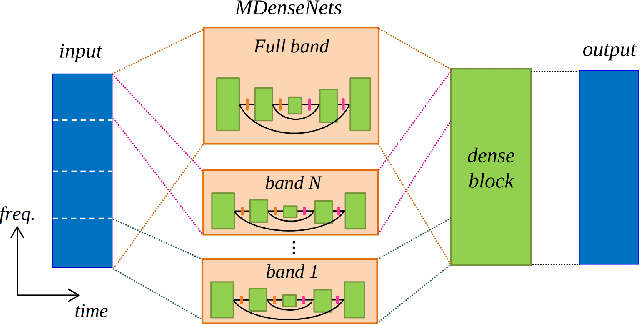
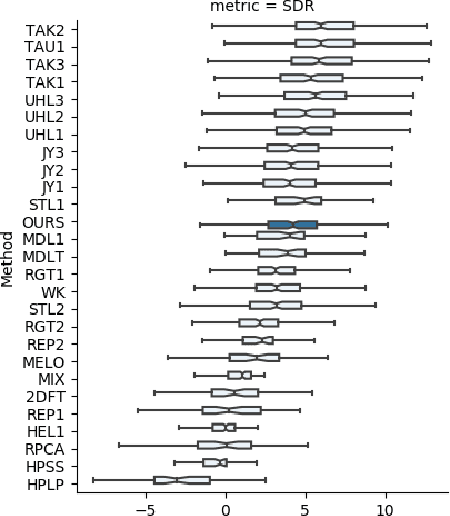
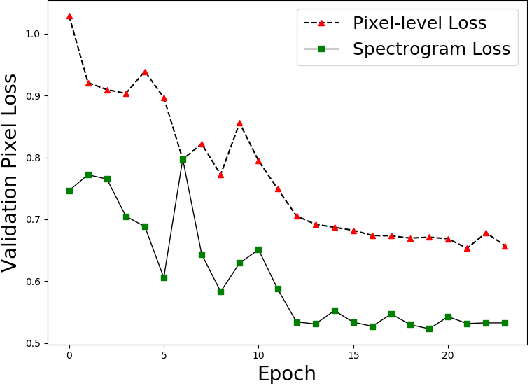
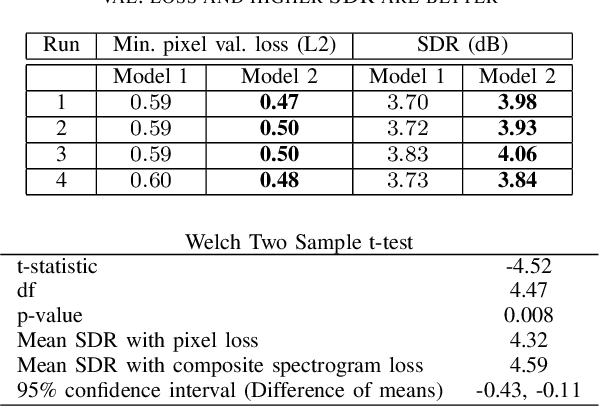
In this paper we study deep learning-based music source separation, and explore using an alternative loss to the standard spectrogram pixel-level L2 loss for model training. Our main contribution is in demonstrating that adding a high-level feature loss term, extracted from the spectrograms using a VGG net, can improve separation quality vis-a-vis a pure pixel-level loss. We show this improvement in the context of the MMDenseNet, a State-of-the-Art deep learning model for this task, for the extraction of drums and vocal sounds from songs in the musdb18 database, covering a broad range of western music genres. We believe that this finding can be generalized and applied to broader machine learning-based systems in the audio domain.
* provided greater details on model parameters (result unchanged);
small correction in plot legend
Via