 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnmasking the giant: A comprehensive evaluation of ChatGPT's proficiency in coding algorithms and data structures
Jul 16, 2023The transformative influence of Large Language Models (LLMs) is profoundly reshaping the Artificial Intelligence (AI) technology domain. Notably, ChatGPT distinguishes itself within these models, demonstrating remarkable performance in multi-turn conversations and exhibiting code proficiency across an array of languages. In this paper, we carry out a comprehensive evaluation of ChatGPT's coding capabilities based on what is to date the largest catalog of coding challenges. Our focus is on the python programming language and problems centered on data structures and algorithms, two topics at the very foundations of Computer Science. We evaluate ChatGPT for its ability to generate correct solutions to the problems fed to it, its code quality, and nature of run-time errors thrown by its code. Where ChatGPT code successfully executes, but fails to solve the problem at hand, we look into patterns in the test cases passed in order to gain some insights into how wrong ChatGPT code is in these kinds of situations. To infer whether ChatGPT might have directly memorized some of the data that was used to train it, we methodically design an experiment to investigate this phenomena. Making comparisons with human performance whenever feasible, we investigate all the above questions from the context of both its underlying learning models (GPT-3.5 and GPT-4), on a vast array sub-topics within the main topics, and on problems having varying degrees of difficulty.
Kinetic Song Comprehension: Deciphering Personal Listening Habits via Phone Vibrations
Sep 19, 2019
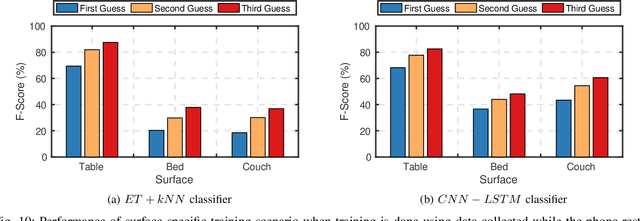

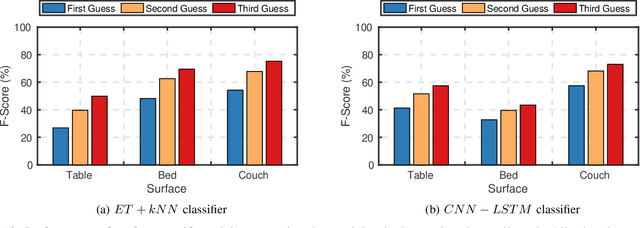
Music is an expression of our identity, showing a significant correlation with other personal traits, beliefs, and habits. If accessed by a malicious entity, an individual's music listening habits could be used to make critical inferences about the user. In this paper, we showcase an attack in which the vibrations propagated through a user's phone while playing music via its speakers can be used to detect and classify songs. Our attack shows that known songs can be detected with an accuracy of just under 80%, while a corpus of 100 songs can be classified with an accuracy greater than 80%. We investigate such questions under a wide variety of experimental scenarios involving three surfaces and five phone speaker volumes. Although users can mitigate some of the risk by using a phone cover to dampen the vibrations, we show that a sophisticated attacker could adapt the attack to still classify songs with a decent accuracy. This paper demonstrates a new way in which motion sensor data can be leveraged to intrude on user music preferences without their express permission. Whether this information is leveraged for financial gain or political purposes, our research makes a case for why more rigorous methods of protecting user data should be utilized by companies, and if necessary, individuals.